Alors que les moteurs d'IA basés sur la conversation comme ChatGPT Search, Gemini, Claude et Perplexity redéfinissent la façon dont les utilisateurs trouvent des informations, les webmasters sont confrontés à un défi fondamental : comment rendre nos sites Web lisibles pour l'intelligence artificielle ?
Traditionnellement, les robots des moteurs de recherche (comme Googlebot) lisent les structures HTML et les plans de site pour indexer les pages. Aujourd'hui, les robots IA (comme GPTBot et ClaudeBot) ingérez, résumez et citez des pages Web avec des réponses en temps réel.
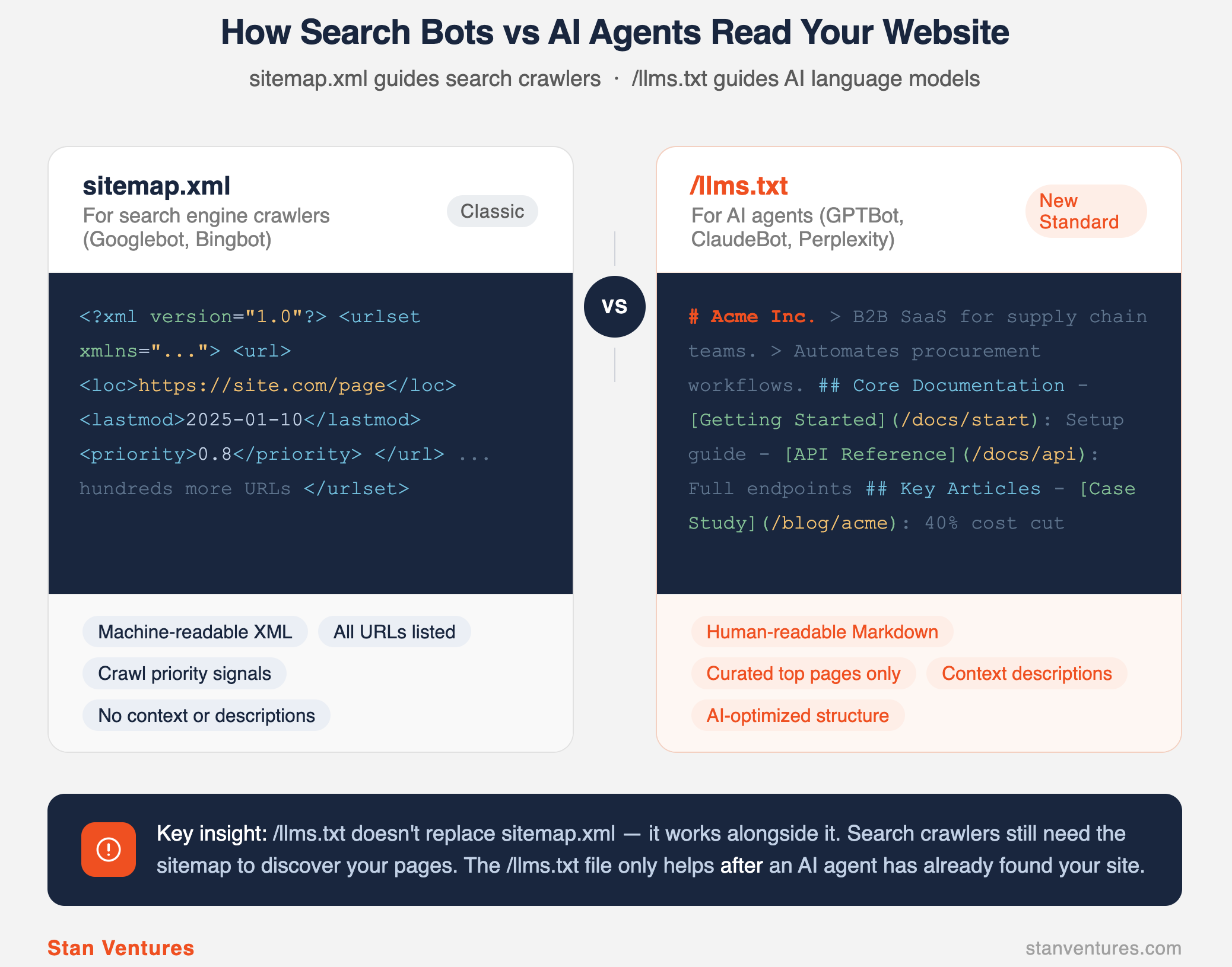
Pour combler cet écart, une spécification communautaire a émergé : le Norme `/llms.txt` (documenté à llmstxt.org). Placé à la racine d'un domaine, il fait office de plan de site conçu spécifiquement pour les LLM.
Mais à mesure que la recherche par l’IA émerge, /llms.txt une véritable avancée en matière de visibilité, ou s’agit-il d’une distraction technique surfaite ?
Dans ce guide, nous décomposons ce que /llms.txt c'est-à-dire, analyser ses mécanismes de base, répondre aux critiques critiques de l'industrie émanant des autorités de recherche et définir qui devrait – et ne devrait pas – le mettre en œuvre.
Qu'est-ce que « /llms.txt » ?
Semblable à la façon dont robots.txt spécifie les fichiers que les robots d'exploration Web ne devrait pas touche, /llms.txt est un fichier Markdown brut qui fournit une feuille de route organisée et à signal élevé des pages que les agents d'IA *devraient* lire.
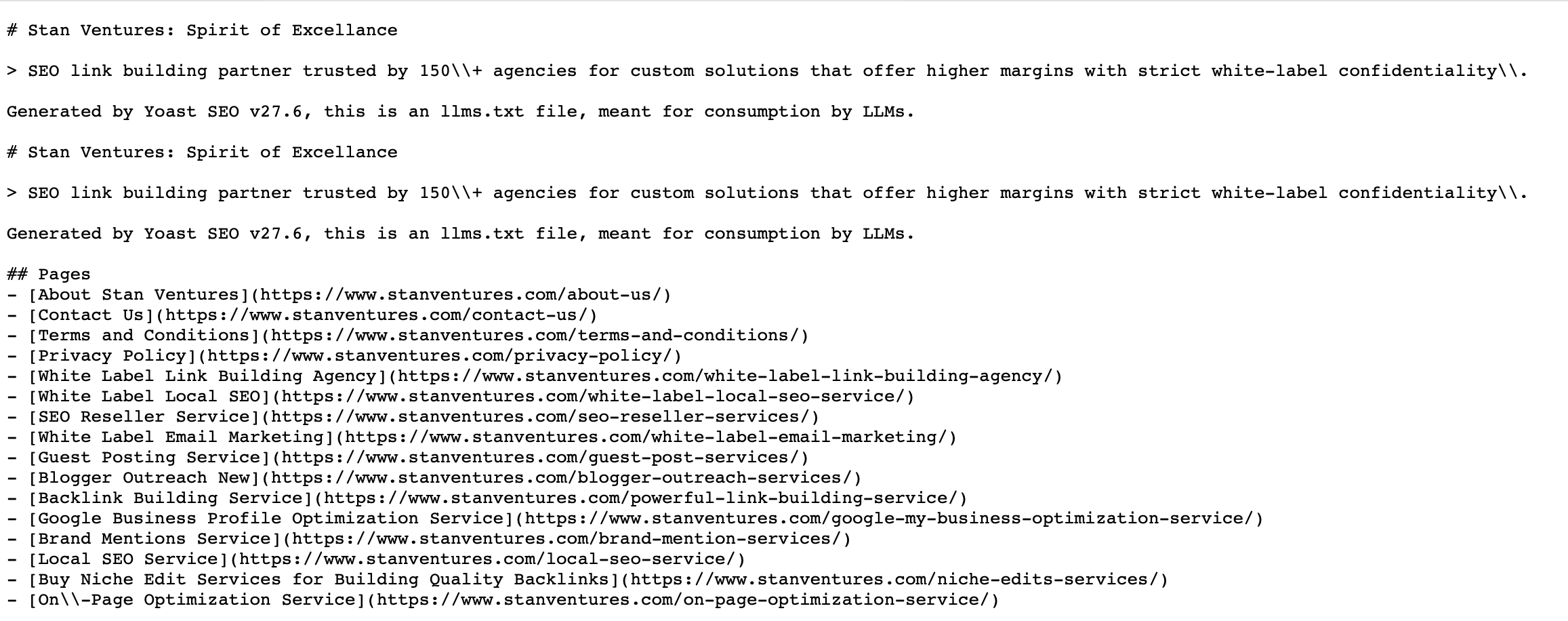
Le format standard
Placé dans le répertoire racine (par exemple, votredomaine.com/llms.txt), le dossier est composé de :
- En-tête H1 (obligatoire) : Le nom de l'organisation ou du projet.
- Citation de bloc (recommandé) : Un résumé concis et de haut niveau de ce que fait le site, aidant le LLM à orienter immédiatement son contexte.
- Sections H2 (liens catégorisés) : Une liste structurée à puces de liens vers vos ressources canoniques de plus grande valeur (par exemple, documentation de base, articles, pages de produits). Chaque lien est associé à un bref résumé descriptif de son contenu.
- Fichiers compagnon (par exemple, `/llms-full.txt`) : Un fichier complet unique et facultatif contenant le texte intégral de vos pages clés dans Markdown, permettant à un LLM d'ingérer les principales informations de votre site en une seule requête.
Une confrontation cruciale avec la réalité : « Découverte » contre « Fonctionnalité »
Une idée fausse courante dans le domaine du marketing numérique est que la création d'un /llms.txt Le fichier est un facteur de classement SEO qui augmentera comme par magie le classement d'un site Web dans Google ou ChatGPT.

Comme l'a récemment souligné John Mueller (responsable des relations de recherche chez Google), il est essentiel de séparer la « découverte » de la « fonctionnalité » :
Découverte (SEO) : Le processus par lequel un moteur de recherche mondial trouve votre site Web et vos pages en premier lieu.
Fonctionnalité (UX pour les agents) : Une fois agent ou moteur de recherche est déjà arrivé sur la page, l'aidant à accomplir sa tâche avec une précision maximale et un minimum de frais généraux.
« Vous ne les faites pas pour le référencement (pour être trouvé), mais si vous êtes responsable du site Web dans son ensemble, garantir un « taux de découverte » (SEO) élevé ainsi qu'un taux de conversion élevé est utile pour justifier votre travail.
— John Mueller
À quoi ne pas s'attendre (la réalité de la découverte)
Les moteurs de réponse IA ne parcourent pas seuls l’Internet brut en temps réel pour chaque requête. Au lieu de cela, lorsqu'un utilisateur pose une question, ChatGPT Search ou Perplexity exécute une requête sur un index de moteur de recherche standard (comme l'API de Bing) pour récupérer les 10 à 20 premières pages de classement.
Si votre site Web ne dispose pas d'une autorité de recherche traditionnelle et ne figure pas dans les premiers résultats des moteurs de recherche, le robot d'exploration IA ne découvrira jamais votre site et ne lira jamais votre fichier `/llms.txt`.
/llms.txt ne contourne pas le besoin de bases SEO de base ; cela ne fait qu'améliorer ce qui se passe après votre page est récupérée.
À quoi s'attendre (les véritables avantages fonctionnels)
Si votre site Web est déjà bien classé et est régulièrement consulté par les robots de recherche IA, /llms.txt offre des avantages fonctionnels substantiels :
Précision dans les citations IA : Les moteurs d'IA synthétisent plusieurs pages Web pour écrire une seule réponse. Si un robot lit votre /llms.txt fichier, il reçoit un résumé très structuré et précis de la structure de votre site, réduisant ainsi le risque que le moteur interprète mal votre marque ou hallucine des faits sur votre entreprise.
Lisibilité du pipeline RAG : De nombreuses entreprises créent des outils d’IA internes et des assistants personnalisés. Ces systèmes explorent les ressources de l'industrie à l'aide de RAG (Retrieval-Augmented Generation). Exposer /llms.txt agit comme une invitation ouverte aux entreprises B2B à synchroniser de manière transparente vos informations dans leurs bases de données personnalisées, faisant ainsi de votre marque une source de données fondamentale.
Efficacité du serveur : Les robots d'exploration IA peuvent imposer une charge importante aux serveurs Web en demandant à plusieurs reprises des pages HTML surchargées. En dirigeant les agents vers un répertoire centralisé de fichiers Markdown légers, vous réduisez considérablement la bande passante du serveur et la surcharge de traitement.
Qui devrait et ne devrait pas utiliser « /llms.txt » ?
Suivant la règle de « donner la priorité aux besoins avant les rêves », en mettant en œuvre /llms.txt n'est pas une priorité pour tout le monde.

Qui devrait l’utiliser :
Portails de développeurs et fournisseurs d'API : Les assistants de codage d'IA (Cursor, GitHub Copilot) s'appuient fortement sur l'analyse des documents des développeurs. Avoir une carte propre est très précieux pour la génération de code.
Marques techniques B2B et SaaS : Entreprises qui publient des guides détaillés, des livres blancs de recherche ou des références logicielles dans lesquels le public cible utilise des outils d'IA pour rechercher des décisions d'achat.
Bases de données éducatives à grand volume : Les établissements universitaires, les bibliothèques de recherche et les bases de données qui souhaitent que leurs documents publics soient cités avec précision par les systèmes de recherche conversationnelle.
Qui devrait l’ignorer (pour l’instant) :
Entreprises locales de brique et de mortier : Un plombier ou un dentiste local est découvert via des cartes et des avis d'intention locaux. Un /llms.txt Le fichier ne générera pas de trafic piétonnier ni n’améliorera le classement des cartes locales.
Sites de commerce électronique B2C généraux : Les journaux du serveur montrent aujourd’hui un trafic d’achat transactionnel négligeable généré par des agents autonomes. Construire des répertoires personnalisés pour des agents inexistants est un rêve spéculatif.
Sites avec de mauvaises bases SEO : Si un site est en proie à des vitesses de chargement lentes, à des boucles de redirection interrompues ou à un contenu léger et de mauvaise qualité, les heures des développeurs sont bien mieux consacrées à la réparation de ces éléments de découverte fondamentaux.
Regarder vers l'avenir
Le /llms.txt Le fichier est actuellement une initiative communautaire, mais sa logique sous-jacente est solide.
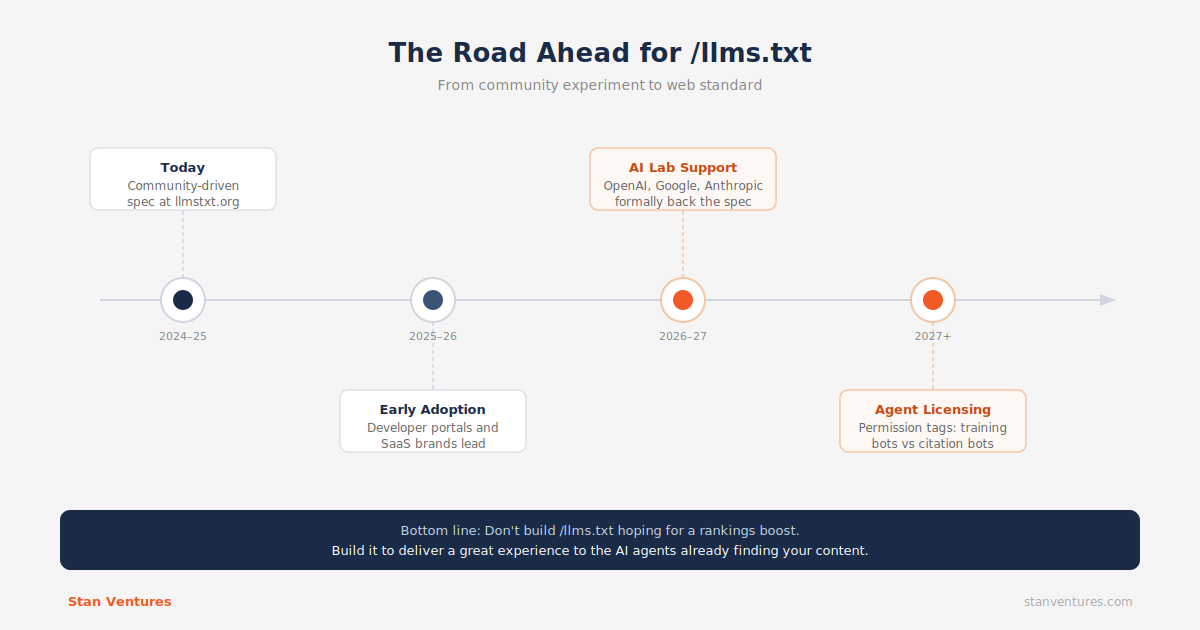
À mesure que le Web s’adapte à l’IA, nous pouvons nous attendre à :
Normalisation formelle : Les principaux laboratoires d'IA (OpenAI, Google, Anthropic) ou les organismes de normalisation (comme le W3C) pourraient éventuellement codifier une norme d'annuaire universelle lisible par machine pour économiser la bande passante d'exploration.
Protocoles de licence d'agent : /llms.txt peut évoluer pour inclure des balises d'autorisation qui font la distinction entre les moteurs de recherche (qui génèrent le trafic de citations) et les robots de formation de modèles (qui récupèrent les données pour former des modèles sans retour de trafic), donnant aux webmasters un contrôle granulaire sur leur propriété intellectuelle.
L’essentiel : Ne construisez pas un /llms.txt annuaire dans l’espoir d’une augmentation soudaine dans les classements Google. Construisez-le pour offrir une excellente « expérience utilisateur » aux agents d’IA qui trouvent déjà leur chemin vers votre contenu.

Dileep Thekkethil est le directeur du marketing chez Stan Ventures, où il applique plus de 15 ans d'expertise en référencement et en marketing numérique pour stimuler la croissance et l'autorité. Ancien journaliste avec six ans d'expérience, il combine narration stratégique et savoir-faire technique pour aider les marques à naviguer dans la transition vers des moteurs de recherche et génératifs basés sur l'IA. Dileep est un ardent défenseur des normes EEAT de Google, partageant régulièrement des cas d'utilisation et des scénarios réels pour démystifier les tendances marketing complexes. C'est un jardinier passionné de fruits tropicaux, un passionné d'automobile et un gardien dévoué de sa paire de calopsittes.