
Note de l’éditeur: Alors que 2021 tire à sa fin, nous célébrons avec un compte à rebours des 12 jours de Noël des articles d’experts les plus populaires et les plus utiles sur Search Engine Journal cette année.
Cette collection a été organisée par notre équipe éditoriale en fonction des performances, de l’utilité, de la qualité et de la valeur créée pour vous, nos lecteurs, de chaque article.
Chaque jour jusqu’au 24 décembre, nous republierons l’une des meilleures colonnes de l’année, en commençant par le n°12 et en comptant jusqu’au n°1. Notre compte à rebours commence aujourd’hui avec notre chronique n°5, qui a été initialement publiée le 4 août. , 2021.
Ce guide pratique d’Andrea Atzori enseigne aux lecteurs comment utiliser Google Sheets pour le scraping Web et la création de campagnes, sans aucune expérience de codage requise.
Profitez!
Nous avons tous été dans une situation où nous avons dû extraire des données d’un site Web à un moment donné.
Lorsque vous travaillez sur un nouveau compte ou une nouvelle campagne, il se peut que vous ne disposiez pas des données ou des informations disponibles pour la création des annonces, par exemple.
Publicité
Continuer la lecture ci-dessous
Dans un monde idéal, nous aurions reçu tout le contenu, les pages de destination et les informations pertinentes dont nous avons besoin, dans un format facile à importer, tel qu’un fichier CSV, une feuille de calcul Excel ou une feuille Google. (Ou à tout le moins, à condition que nous ayons besoin de données tabulées pouvant être importées dans l’un des formats susmentionnés.)
Mais ce n’est pas toujours comme ça que ça se passe.
Ceux qui n’avaient pas les outils pour le scraping Web – ou les connaissances en codage pour utiliser quelque chose comme Python pour aider à la tâche – ont peut-être dû recourir au travail fastidieux de copier et coller manuellement des centaines ou des milliers d’entrées.
Dans un emploi récent, mon équipe a été invitée à :
- Accédez au site Web du client.
- Téléchargez plus de 150 nouveaux produits répartis sur 15 pages différentes.
- Copiez et collez le nom du produit et l’URL de la page de destination de chaque produit dans une feuille de calcul.
Maintenant, vous pouvez imaginer à quel point la tâche aurait été longue si nous avions fait exactement cela et exécuté la tâche manuellement.
Publicité
Continuer la lecture ci-dessous
Non seulement cela prend du temps, mais avec quelqu’un qui parcourt manuellement autant d’éléments et de pages et doit physiquement copier et coller les données produit par produit, les chances de faire une erreur ou deux sont assez élevées.
Il faudrait alors encore plus de temps pour examiner le document et s’assurer qu’il était exempt d’erreurs.
Il doit y avoir une meilleure façon.
Bonne nouvelle : il y a ! Laissez-moi vous montrer comment nous avons fait.
Qu’est-ce que IMPORTXML ?
Entrez Google Sheets. J’aimerais que vous rencontriez la fonction IMPORTXML.
Selon Google page d’assistance, IMPORTXML « importe des données à partir de n’importe quel type de données structurées, y compris les flux XML, HTML, CSV, TSV et RSS et ATOM XML ».
Essentiellement, IMPORTXML est une fonction qui vous permet de récupérer des données structurées à partir de pages Web – aucune connaissance en codage n’est requise.
Par exemple, il est simple et rapide d’extraire des données telles que des titres de pages, des descriptions ou des liens, mais aussi des informations plus complexes.
Comment IMPORTXML peut-il aider à gratter les éléments d’une page Web ?
La fonction elle-même est assez simple et ne nécessite que deux valeurs :
- L’URL de la page Web à partir de laquelle nous avons l’intention d’extraire ou de récupérer les informations.
- Et le XPath de l’élément dans lequel les données sont contenues.
XPath signifie Langage de chemin XML et peut être utilisé pour parcourir les éléments et les attributs d’un document XML.
Par exemple, pour extraire le titre de la page de https://en.wikipedia.org/wiki/Moon_landing, nous utiliserions :
=IMPORTXML (« https://en.wikipedia.org/wiki/Moon_landing », « //titre »)
Cela renverra la valeur : Atterrissage sur la Lune – Wikipédia.
Ou, si nous recherchons la description de la page, essayez ceci :
=IMPORTXML (« https://www.searchenginejournal.com/ », »//meta[@name=’description’]/@contenu »)
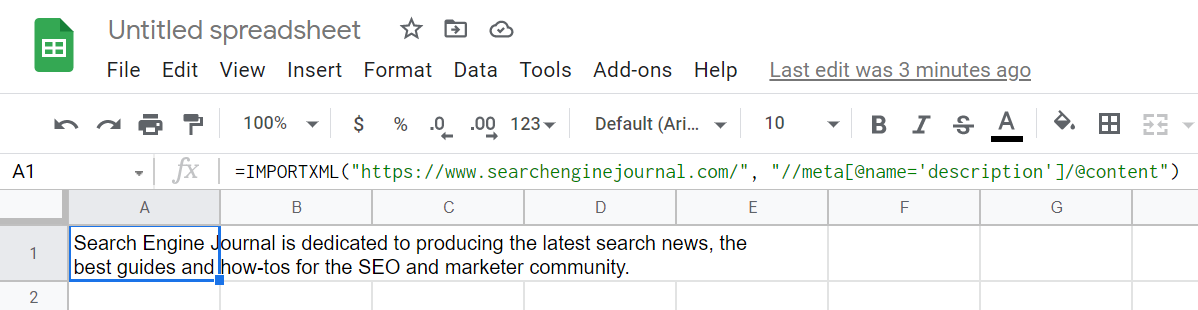
Voici une liste restreinte de certaines des requêtes XPath les plus courantes et les plus utiles :
Publicité
Continuer la lecture ci-dessous
- Titre de la page : //titre
- Méta description de la page : // méta[@name=’description’]/@contenu
- Page H1 : //h1
- Liens vers les pages : //@href
Voir IMPORTXML en action
Depuis la découverte d’IMPORTXML dans Google Sheets, il est vraiment devenu l’une de nos armes secrètes dans l’automatisation de bon nombre de nos tâches quotidiennes, de la création de campagnes et d’annonces à la recherche de contenu, et plus encore.
De plus, la fonction combinée à d’autres formules et modules complémentaires peut être utilisée pour des tâches plus avancées qui nécessiteraient autrement des solutions et un développement sophistiqués, tels que des outils construits en Python.
Mais dans ce cas, nous examinerons IMPORTXML sous sa forme la plus basique : extraire les données d’une page Web.
Voyons un exemple pratique.
Imaginez qu’on nous demande de créer une campagne pour le Search Engine Journal.
Ils aimeraient que nous publiions les 30 derniers articles publiés dans la section PPC du site Web.
Publicité
Continuer la lecture ci-dessous
Une tâche assez simple, pourrait-on dire.
Malheureusement, les éditeurs ne sont pas en mesure de nous envoyer les données et nous ont gentiment demandé de nous référer au site Web pour rechercher les informations nécessaires à la mise en place de la campagne.
Comme mentionné au début de notre article, une façon de procéder serait d’ouvrir deux fenêtres de navigateur – une avec le site Web et l’autre avec Google Sheets ou Excel. Nous commencions alors à copier et coller les informations, article par article et lien par lien.
Mais en utilisant IMPORTXML dans Google Sheets, nous pouvons obtenir le même résultat avec peu ou pas de risque de faire des erreurs, en une fraction du temps.
Voici comment.
Étape 1 : Commencez avec une nouvelle feuille Google
Tout d’abord, nous ouvrons un nouveau document Google Sheets vierge :
Étape 2 : ajoutez le contenu dont vous avez besoin pour gratter
Ajoutez l’URL de la page (ou des pages) à partir de laquelle nous voulons extraire les informations.
Publicité
Continuer la lecture ci-dessous
Dans notre cas, nous commençons par https://www.searchenginejournal.com/category/pay-per-click/ :
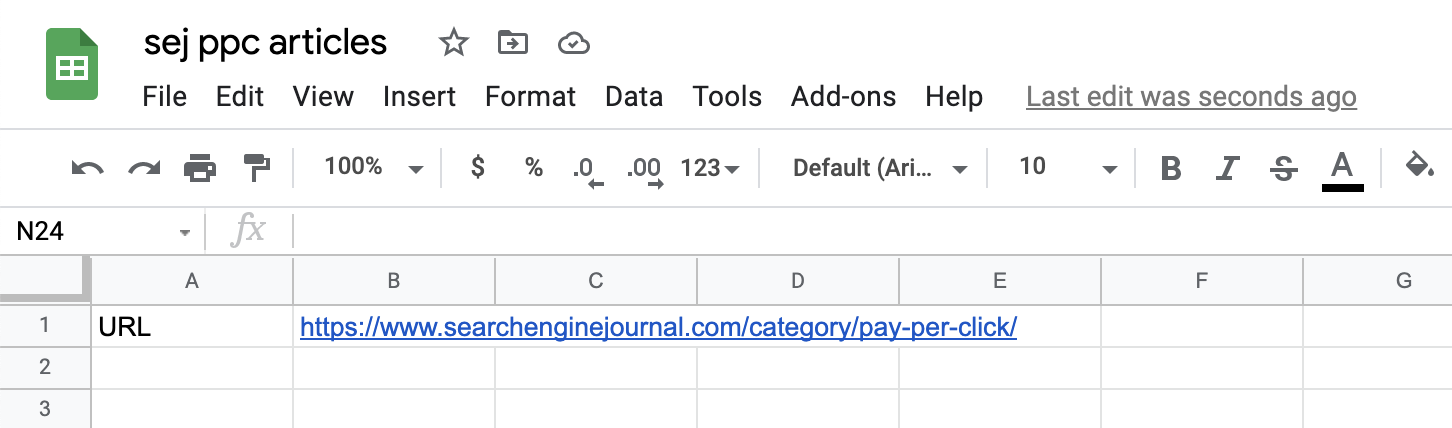 Capture d’écran tirée de Google Sheets, juillet 2021
Capture d’écran tirée de Google Sheets, juillet 2021Étape 3 : Trouvez le XPath
Nous trouvons le XPath de l’élément dont nous voulons importer le contenu dans notre feuille de calcul de données.
Dans notre exemple, commençons par les titres des 30 derniers articles.
Dirigez-vous vers Chrome. Après avoir survolé le titre de l’un des articles, faites un clic droit et sélectionnez Inspecter.
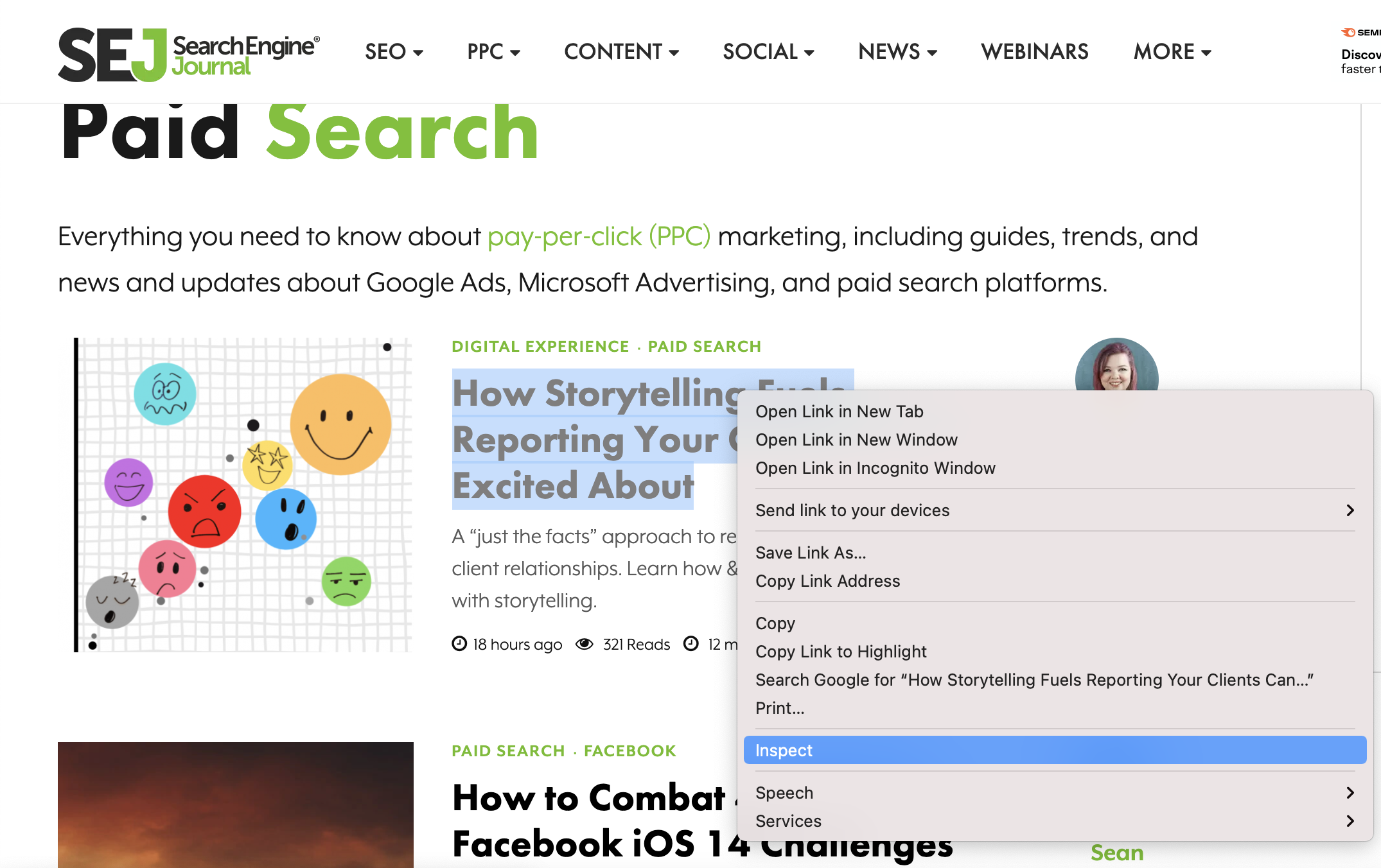 Capture d’écran de SearchEngineJournal.com, juillet 2021
Capture d’écran de SearchEngineJournal.com, juillet 2021Cela ouvrira la fenêtre Chrome Dev Tools :
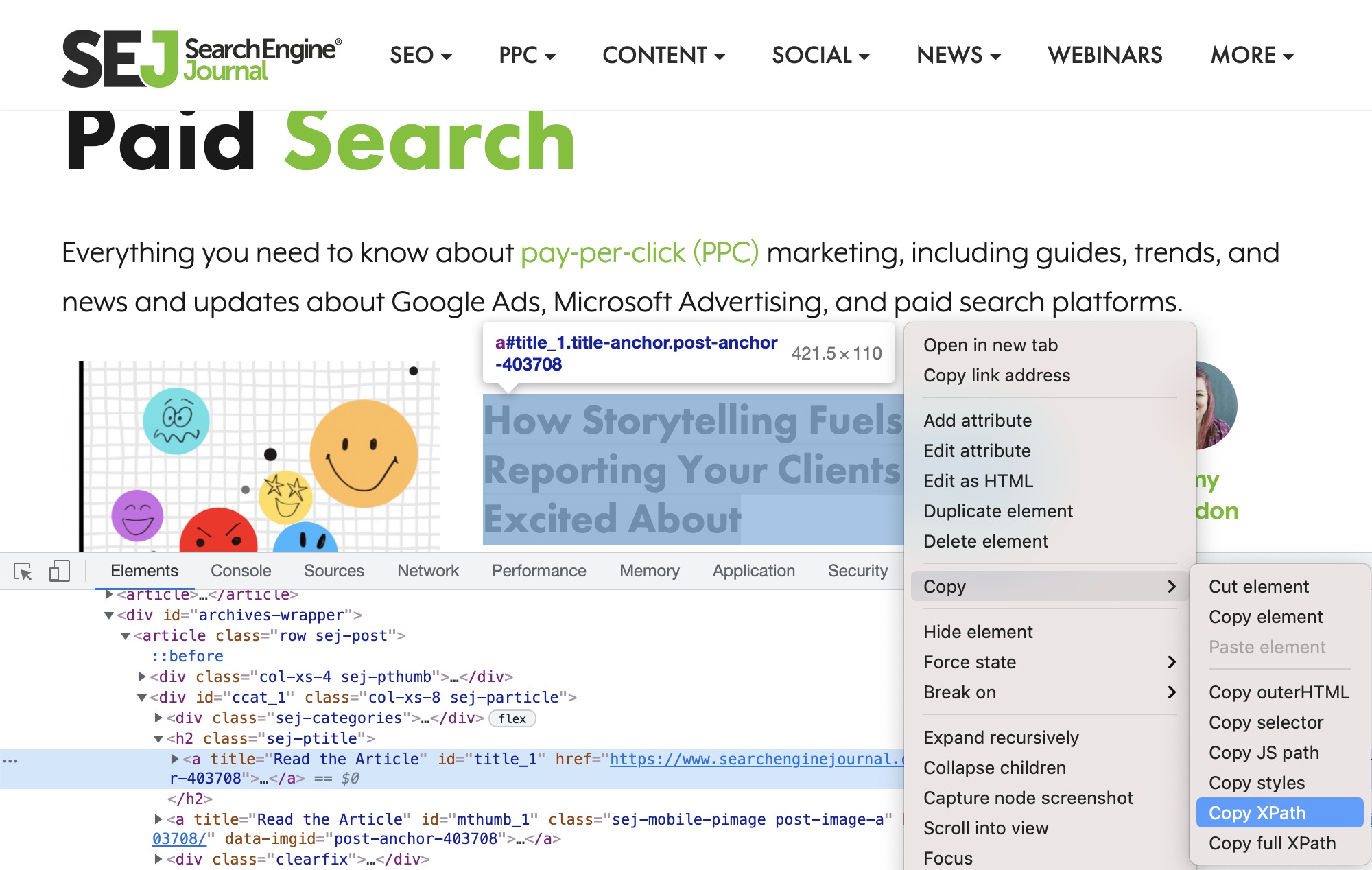 Capture d’écran de SearchEngineJournal.com, juillet 2021
Capture d’écran de SearchEngineJournal.com, juillet 2021Assurez-vous que le titre de l’article est toujours sélectionné et mis en surbrillance, puis cliquez à nouveau avec le bouton droit et choisissez Copier > Copier XPath.
Publicité
Continuer la lecture ci-dessous
Étape 4: extraire les données dans Google Sheets
De retour dans votre document Google Sheets, présentez la fonction IMPORTXML comme suit :
=IMPORTERXML(B1, »//*[starts-with(@id, ‘title’)]”)
Quelques points à noter :
D’abord, dans notre formule, nous avons remplacé l’URL de la page par la référence à la cellule où est stockée l’URL (B1).
Seconde, lors de la copie du XPath à partir de Chrome, celui-ci sera toujours entouré de guillemets doubles.
(//*[@id=”title_1″])
Cependant, afin de s’assurer que cela ne brise pas la formule, le signe des guillemets doubles devra être remplacé par le signe des guillemets simples.
(//*[@id=’title_1’])
Notez que dans ce cas, comme le titre de l’ID de page change pour chaque article (title_1, title_2, etc), nous devons légèrement modifier la requête et utiliser « starts-with » afin de capturer tous les éléments de la page avec un ID qui contient ‘Titre.’
Voici à quoi cela ressemble sur le document Google Sheets :
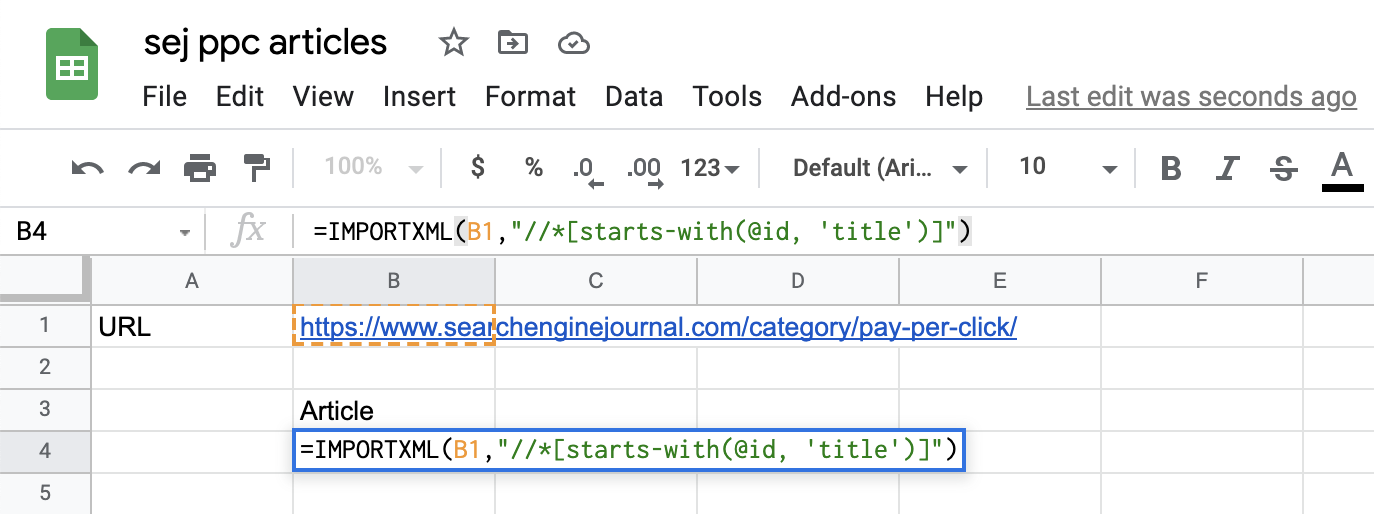 Capture d’écran tirée de Google Sheets, juillet 2021
Capture d’écran tirée de Google Sheets, juillet 2021Et en quelques instants, voici à quoi ressemblent les résultats une fois que la requête a chargé les données dans la feuille de calcul :
 Capture d’écran tirée de Google Sheets, juillet 2021
Capture d’écran tirée de Google Sheets, juillet 2021Comme vous pouvez le voir, la liste renvoie tous les articles présentés sur la page que nous venons de gratter (y compris mon article précédent sur l’automatisation et comment utiliser les personnalisateurs publicitaires pour améliorer les performances de la campagne Google Ads).
Publicité
Continuer la lecture ci-dessous
Vous pouvez également l’appliquer à la récupération de tout autre élément d’information nécessaire à la configuration de votre campagne publicitaire.
Ajoutons les URL des pages de destination, l’extrait vedette de chaque article et le nom de l’auteur dans notre document Sheets.
Pour les URL des pages de destination, nous devons ajuster la requête pour spécifier que nous sommes après l’élément HREF attaché au titre de l’article.
Par conséquent, notre requête ressemblera à ceci :
=IMPORTERXML(B1, »//*[starts-with(@id, ‘title’)]/@href”)
Maintenant, ajoutez ‘/@href’ à la fin du Xpath.
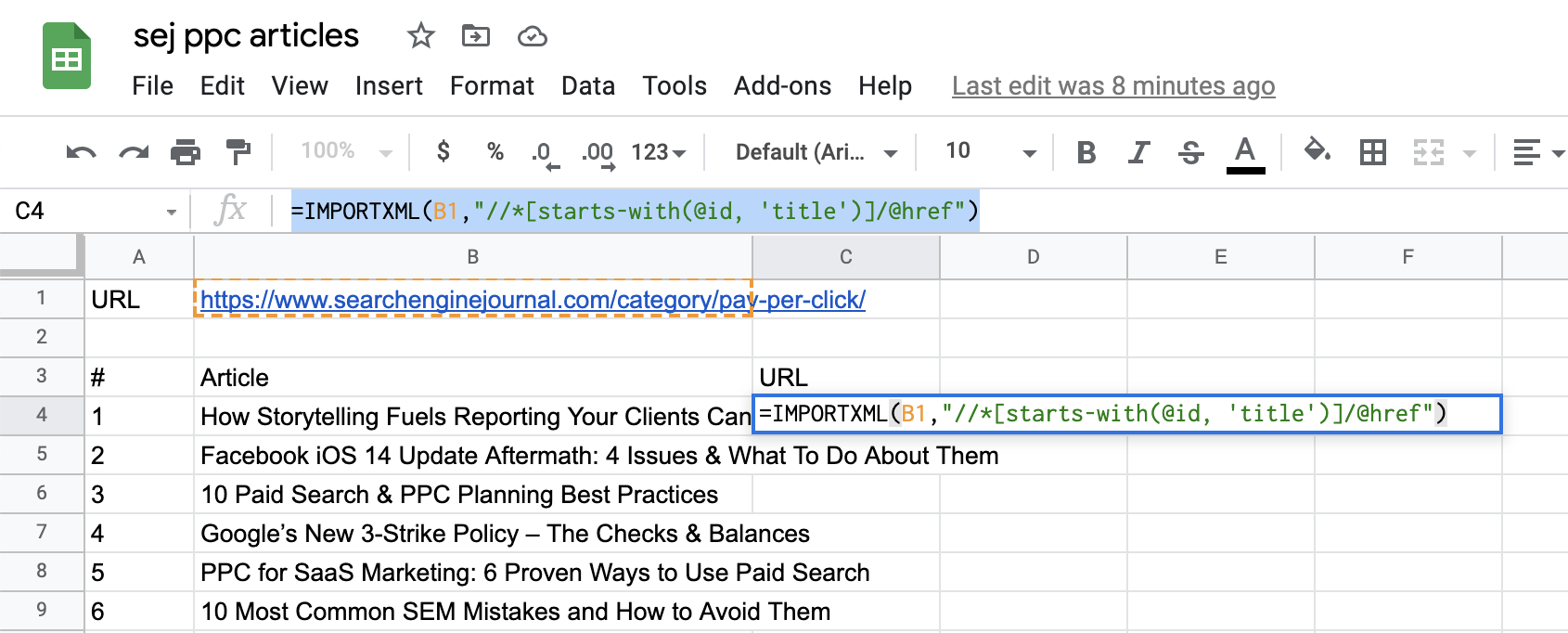 Capture d’écran tirée de Google Sheets, juillet 2021
Capture d’écran tirée de Google Sheets, juillet 2021Voila ! On a tout de suite les URL des landing pages :
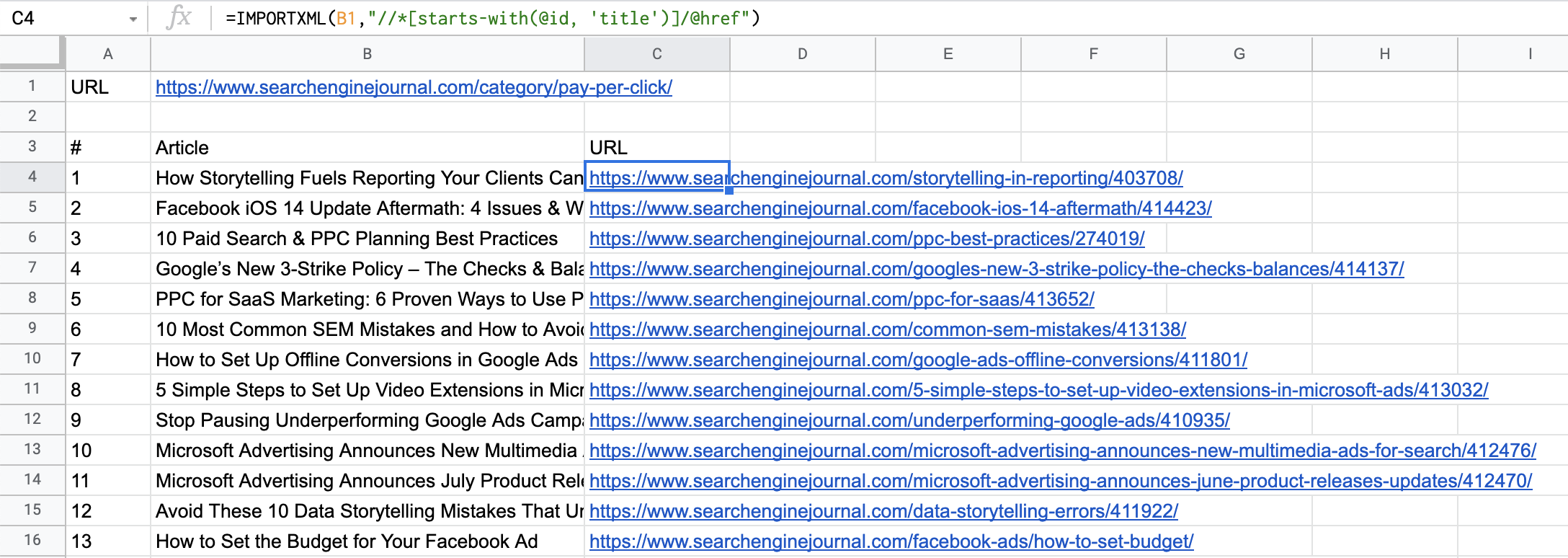 Capture d’écran tirée de Google Sheets, juillet 2021
Capture d’écran tirée de Google Sheets, juillet 2021Vous pouvez faire de même pour les extraits en vedette et les noms d’auteur :
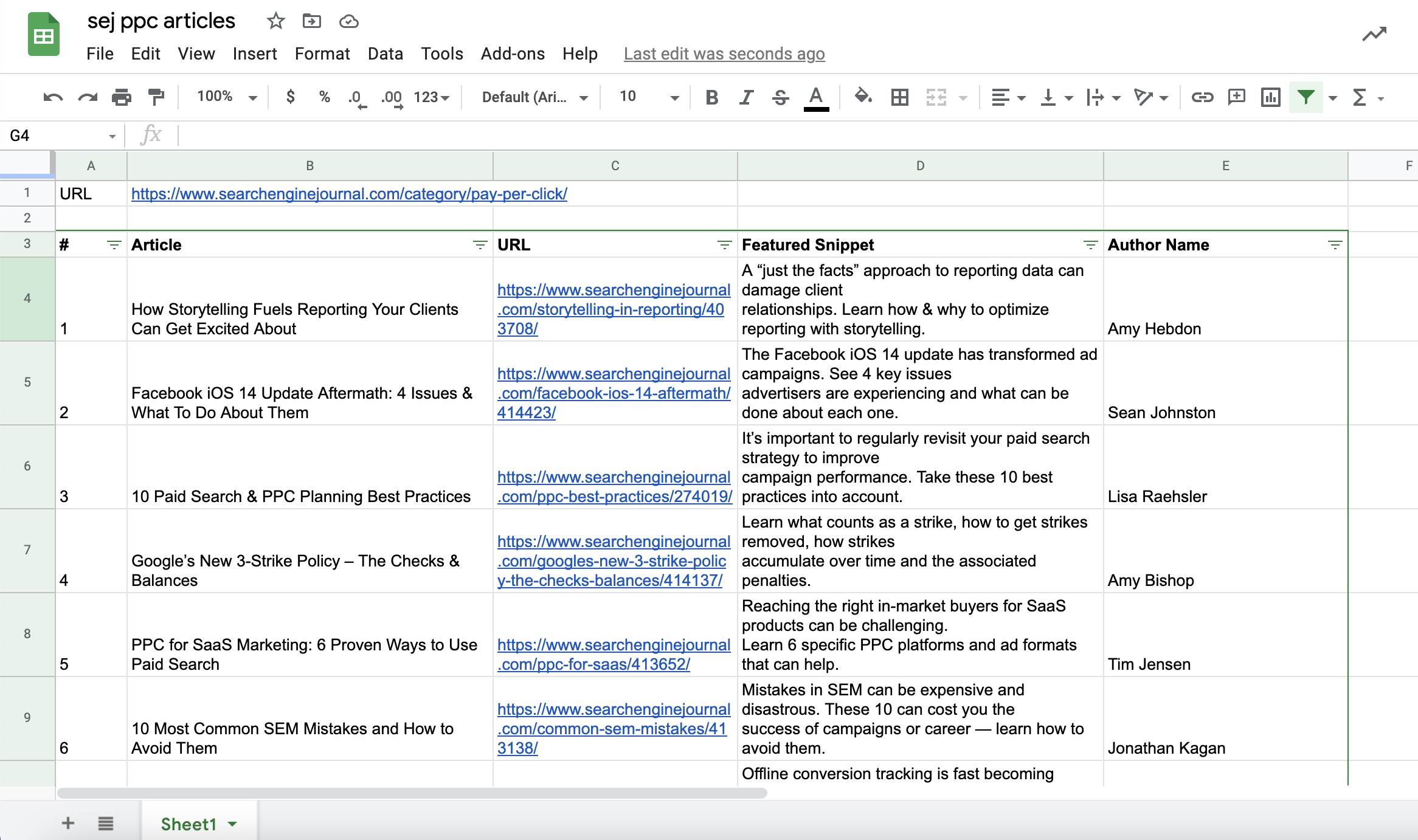 Capture d’écran tirée de Google Sheets, juillet 2021
Capture d’écran tirée de Google Sheets, juillet 2021Dépannage
Une chose dont il faut se méfier est que pour pouvoir développer et remplir complètement la feuille de calcul avec toutes les données renvoyées par la requête, la colonne dans laquelle les données sont renseignées doit avoir suffisamment de cellules libres et aucune autre donnée sur le chemin.
Publicité
Continuer la lecture ci-dessous
Cela fonctionne de la même manière que lorsque nous utilisons un ARRAYFORMULA, pour que la formule se développe, il ne doit pas y avoir d’autres données dans la même colonne.
Conclusion
Et là, vous disposez d’un moyen entièrement automatisé et sans erreur de récupérer les données de (potentiellement) n’importe quelle page Web, que vous ayez besoin du contenu et des descriptions de produits, ou de données de commerce électronique telles que le prix du produit ou les frais d’expédition.
À une époque où les informations et les données peuvent être l’avantage requis pour fournir des résultats supérieurs à la moyenne, la capacité de scraper des pages Web et du contenu structuré de manière simple et rapide peut être inestimable. De plus, comme nous l’avons vu plus haut, IMPORTXML peut aider à réduire les temps d’exécution et les risques d’erreurs.
De plus, la fonction n’est pas seulement un excellent outil qui peut être exclusivement utilisé pour les tâches PPC, mais peut également être très utile dans de nombreux projets différents qui nécessitent un scraping Web, y compris les tâches de référencement et de contenu.
Compte à rebours de Noël 2021 SEJ :
Publicité
Continuer la lecture ci-dessous
Image en vedette : Aleutie/Shutterstock

