
La plupart des spécialistes du marketing de contenu pensent à la dégradation de la même manière qu’ils pensent aux dates d’expiration. Une page devient obsolète, le trafic diminue, vous la rafraîchissez, le trafic revient. Simple.
Ce modèle mental fonctionne bien pour la recherche Google traditionnelle. Il est incomplet au moment où vous commencez à optimiser la recherche IA.
Voici ce dont presque personne ne parle : Google et les LLM fonctionnent sur des horloges de désintégration complètement différentes. Google mesure la fraîcheur dans le temps. Les LLM mesurent la fraîcheur dans le consensus. Ces deux horloges peuvent fonctionner dans des directions opposées sur la même page, ce qui signifie qu'un élément de contenu peut parfaitement être classé dans Google tout en étant fonctionnellement invisible dans ChatGPT, Perplexity et Google AI Overviews. Et le playbook standard d’actualisation du contenu ne résoudra pas toujours le problème.
Cet article explique pourquoi ces deux systèmes vieillissent différemment le contenu, comment diagnostiquer quelle horloge est en panne sur une page donnée et que faire à ce sujet.
Le problème des deux horloges
Le signal de fraîcheur de Google est fondamentalement une question de temps. Lorsque Google décide de la fraîcheur d'une page, il s'appuie sur des marqueurs temporels : la date de publication, l'horodatage de la dernière modification, la date à laquelle Googlebot a exploré la page pour la dernière fois, les dates des liens entrants, les dates des citations dans le contenu.
Google a documenté son systèmes de requête mérite-fraîcheur directement : ils existent pour afficher un contenu plus récent pour les requêtes où une récence serait attendue. Un horodatage mis à jour, des liens entrants plus récents et une date de dernière modification claire peuvent modifier un classement Google même si les affirmations sous-jacentes de la page restent inchangées. L'horloge est basée sur un calendrier.
Les LLM ne fonctionnent pas de cette façon. Ils ne voient pas votre horodatage. Ils ne se soucient pas du moment où vos liens entrants ont été placés. Ce qui les intéresse, c'est de savoir si le contenu de votre page correspond toujours au consensus actuel dans leurs données de formation et leur index de récupération.
Le mécanisme derrière cela est génération augmentée par récupérationl'architecture que la plupart des systèmes d'IA modernes utilisent pour ancrer leurs réponses sur les informations actuelles. Lorsqu'un utilisateur pose une question, le système convertit la requête en une intégration vectorielle, puis recherche dans une base de données vectorielle de contenu indexé des morceaux sémantiquement similaires. Les morceaux qui correspondent le mieux sont intégrés à l'invite et façonnent la réponse générée.
Cette distinction est tout. Un LLM compare les revendications sur votre page à un pool beaucoup plus large de revendications provenant de son corpus. Si le consensus dans ce pool a changé, votre page peut être parfaitement actuelle en termes de calendrier tout en étant complètement décalée en termes sémantiques. L’horloge est basée sur le consensus.

Pourquoi ces horloges divergent
Trois mécanismes sont à l’origine de la divergence. Chacun mérite d'être compris car ils créent différents modèles de désintégration qui nécessitent des correctifs différents.
1. Les LLM absorbent les nouveaux consensus plus rapidement qu’ils ne reflètent les mises à jour spécifiques
Lorsqu'un LLM majeur est recyclé ou que son index de récupération est mis à jour, il ingère un énorme volume de contenu récent provenant du Web dans une fenêtre relativement courte. Cela signifie que de nouvelles positions consensuelles peuvent se propager très rapidement via un LLM. Si la majeure partie du contenu récemment publié sur un sujet a été déplacée vers un nouveau cadrage, la représentation interne de ce sujet par le LLM change également, que votre page individuelle ait ou non été mise à jour.
Google fonctionne différemment. Il évalue votre page selon ses propres mérites par rapport à sa requête. Une page bien liée et faisant autorité peut conserver son classement même après que la conversation plus large dans son espace ait évolué, car Google ne compare pas votre page à l'état global du sujet. Le LLM est.
2. La dérive terminologique frappe plus durement les LLM que Google
La terminologie de l’industrie change constamment. Twitter est devenu X. La recherche AI s'appelait autrefois Search Generative Experience, puis Google l'a renommé AI Overviews lors de son événement I/O 2024. L'optimisation générative des moteurs de recherche côtoie l'optimisation de la recherche par l'IA, l'optimisation des moteurs de réponse et une demi-douzaine d'autres étiquettes pour la même idée.
Google gère cela assez bien car il utilise le mappage de synonymes et la résolution d'entités pour comprendre que deux termes différents peuvent faire référence au même concept. Une page sur Twitter peut toujours être classée pour les requêtes liées à X, notamment avec de bons liens internes et des mentions mises à jour.
Les LLM le gèrent avec moins de grâce. Lorsqu'un LLM récupère des morceaux de contenu pour étayer sa réponse, les morceaux doivent correspondre sémantiquement à la requête. Si votre page utilise la terminologie 2022 et la requête utilise la terminologie 2026, la distance d'intégration entre votre contenu et la requête peut être suffisamment grande pour que le système ne présente jamais votre page comme candidate. Vous n'avez pas perdu la citation parce que votre contenu est erroné. Vous l'avez perdu parce que votre vocabulaire est obsolète.
3. La norme factuelle est plus stricte pour les citations de l’IA que pour le classement
Google peut classer une page contenant une affirmation factuelle dans le reste des litiges sur le Web, car Google n'a pas pour mission de vérifier les allégations individuelles au moment de la requête. Il s'agit de faire correspondre les pages aux requêtes.
Les LLM sont différents. Lorsqu’ils intègrent du contenu dans une réponse générée, ils approuvent effectivement la revendication. La plupart des systèmes d’IA modernes incluent des étapes de vérification qui croisent les réclamations avec plusieurs sources. Une page avec une statistique obsolète, un nom de produit obsolète ou un fait qui a depuis été remplacé a beaucoup moins de chances d'être citée, car la citer exposerait le LLM au risque de générer une réponse qui entre en conflit avec d'autres sources de son corpus.
Cela signifie que même de petites inexactitudes, le genre de choses qui n’affecteraient jamais un classement Google, peuvent discrètement tuer la visibilité de l’IA sur une page qui serait autrement forte.
Comment repérer quelle horloge est en panne
Une fois que vous acceptez que la dégradation de Google et la dégradation de LLM sont des problèmes différents, vous avez besoin d'un moyen de les distinguer. Voici le cadre de diagnostic que nous utilisons lors de l'audit du contenu d'un client pour la visibilité de l'IA.
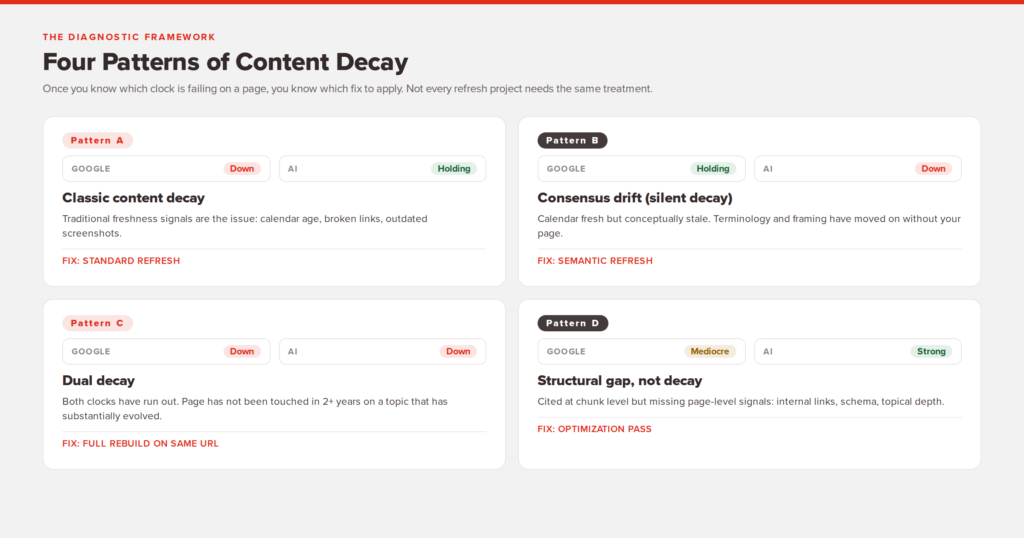
Modèle de symptôme A : baisse du trafic Google, maintien des citations IA
Il s’agit du modèle classique de dégradation du contenu. La page perd sa position dans la recherche traditionnelle, mais elle est toujours attirée par les réponses de l'IA. Diagnostic : les signaux de fraîcheur traditionnels sont en cause. Âge du calendrier, liens rompus, captures d'écran obsolètes, manque de mises à jour récentes. Le playbook d’actualisation standard fonctionnera ici.
Modèle de symptôme B : blocage du trafic Google, baisse des citations IA
C’est le schéma qui échappe à la plupart des gens. La page est toujours classée et attire toujours des visiteurs organiques. Mais lorsque vous le vérifiez dans les aperçus de ChatGPT, Perplexity et AI, vous n'apparaissez plus pour les requêtes que vous aviez l'habitude de gagner. Diagnostic : dérive consensuelle. Votre page est récente mais conceptuellement obsolète. Le correctif ne concerne pas les nouveaux horodatages. Le correctif est une mise à jour sémantique approfondie qui aligne votre terminologie, votre cadrage et vos affirmations factuelles sur le consensus actuel dans votre espace.
Modèle de symptôme C : les deux chutes
Les deux horloges sont écoulées. Il s’agit généralement d’une page qui n’a pas été touchée depuis deux ans ou plus, traitant d’un sujet qui a considérablement évolué. La tentation est d’ajouter une nouvelle date et de dire que c’est terminé. Ne pas. Une page comme celle-ci nécessite une réinitialisation des deux horloges, ce qui signifie une réécriture structurelle et une modernisation du contenu.
Modèle de symptôme D : citations IA fortes, trafic Google médiocre
La page est extraite des réponses de l'IA mais ne les convertit pas en classement traditionnel. Diagnostic : il s'agit généralement d'un problème structurel ou technique, et non d'un problème de dégradation. La page est analysée et citée au niveau du bloc, mais il manque les signaux au niveau de la page dont Google a besoin. Liens internes, schéma, profondeur de couverture, regroupement thématique et Signaux EEAT Les pondérations de Google dans ses principaux systèmes de classement ont tendance à se situer là où se situe l'écart.
Différentes corrections pour différents types de désintégration
Le même modèle d'actualisation en cinq étapes est lancé sur chaque page qui perd de la visibilité, et c'est en partie pourquoi tant de projets d'actualisation ne fonctionnent pas correctement. Voici ce qui fait réellement bouger l’aiguille pour chaque motif.
Pour la désintégration traditionnelle (modèle A) : le rafraîchissement standard
- Mettez à jour l'horodatage et la date de dernière modification.
- Actualisez toutes les statistiques avec les sources de données actuelles.
- Auditez les liens sortants et remplacez tout ce qui est cassé ou obsolète.
- Mettez à jour les captures d'écran et les exemples visuels.
- Ajoutez de nouveaux liens internes à partir de pages récemment publiées.
Pour la dégradation du consensus (modèle B) : le rafraîchissement sémantique
- Vérifiez votre terminologie par rapport aux citations actuelles de l’AI Overview pour vos requêtes cibles. Quels mots et expressions les pages citées utilisent-elles et pas les vôtres ?
- Mettez à jour toutes les allégations qui ont été remplacées par des changements dans le secteur, des changements de marque de produit ou des changements de méthodologie.
- Ajoutez une section qui aborde le cadrage le plus actuel de votre sujet, même si l'ancien cadrage constitue toujours un contexte utile.
- Restructurez vos formats de réponse pour qu'ils correspondent à la manière dont les systèmes d'IA préfèrent extraire les informations : réponse directe d'abord, contexte de support ensuite.
- Mettez également à jour les horodatages, mais comprenez que l’horodatage est la cerise sur le gâteau, pas le gâteau.
Pour le dual decay (modèle C) : la reconstruction
C'est ici que vous arrêtez d'actualiser et commencez à réécrire. La page a besoin d'une nouvelle structure, de revendications actuelles, d'une terminologie moderne et de nouveaux exemples. À ce stade, vous écrivez essentiellement un nouveau contenu sur la même URL, ce qui constitue la mesure la plus puissante que vous puissiez prendre, car vous conservez l'équité des liens existants et l'historique d'exploration de la page tout en réinitialisant les deux horloges.
Pour la dégradation structurelle (modèle D) : la passe d'optimisation
- Auditer les liens internes. Les pages qui sont citées dans AI mais pas dans Google manquent souvent des signaux de lien interne que Google utilise pour évaluer l'autorité thématique.
- Ajoutez ou mettez à jour le balisage de schéma pour aider Google à comprendre les entités et les relations dans le contenu.
- Vérifiez votre cluster thématique. Les pages isolées sont moins performantes que les pages intégrées dans un hub de contenu.
- Passez en revue les méta-titres et les descriptions. Les systèmes d'IA fonctionnent à partir du contenu du corps. Google accorde toujours une grande importance au titre.

Pourquoi c'est important en ce moment
Le trafic de citations de l’IA devient une part significative du trafic organique à forte intention pour la plupart des marques, et l’écart entre les performances de Google et celles de l’IA se creuse. Les pages qui fonctionnent bien depuis des années disparaissent discrètement du pool de citations de l'IA alors que leurs numéros Google semblent stables. Ce type de dégradation silencieuse est le plus dangereux car il n’apparaît dans vos rapports standards que lorsqu’il constitue déjà un problème.
Les équipes qui prennent de l'avance sont celles qui ont cessé de traiter le contenu comme un actif à écriture unique et ont commencé à le traiter comme quelque chose qui nécessite une attention continue sous deux angles : la fraîcheur traditionnelle et l'alignement sémantique avec le consensus actuel.
Cela ne signifie pas que vous devez tout réécrire chaque trimestre. Cela signifie que vous devez savoir quelles pages se détériorent à quelle horloge et appliquer le bon correctif à chacune.
Mettre cela en pratique
Si vous souhaitez savoir lesquelles de vos pages sont supprimées du pool de citations AI, HOTH AI Discover mesure votre visibilité sur ChatGPT, Perplexity, Google AI Overviews et Gemini. Il vous donne une vue page par page de l'endroit où vous êtes cité, des lacunes et des requêtes que vous perdez. Ce sont les données dont vous avez besoin pour distinguer la dégradation traditionnelle de la dégradation consensuelle.
Une fois que vous savez quelles pages doivent être améliorées, HOTH Content Refresh s'occupe du reste. Chaque actualisation comprend au moins 50 % de nouveau contenu, des données et citations actuelles, une structure prête pour l'IA et une passe terminologique modernisée. Il est conçu exactement pour le type de dégradation de la double horloge décrit dans cet article, car la plupart des projets d'actualisation en 2026 nécessitent à la fois des mises à jour du calendrier et des mises à jour consensuelles pour réellement faire bouger les choses.
Pour une lecture plus large sur le fonctionnement des signaux de fraîcheur de l'IA et sur la manière d'empêcher le contenu persistant de devenir obsolète, consultez notre guide plus détaillé sur la fraîcheur du contenu dans les citations de l'IA et notre analyse de la dérive sémantique et de la dégradation du contenu.
Si vous préférez que notre équipe gère l'audit et les actualisations pour vous dans l'ensemble de votre bibliothèque, réservez un appel et nous parcourrons votre site, identifierons les modèles de désintégration qui apparaissent où et élaborerons une feuille de route d'actualisation qui corrige les deux horloges à la fois.

