
« Indexé, bien que bloqué par le fichier robots.txt » s’affiche dans la Google Search Console (GSC) lorsque Google a indexé des URL qu’il n’est pas autorisé à explorer.
Dans la plupart des cas, ce sera un problème simple où vous avez bloqué l’exploration dans votre fichier robots.txt. Mais il y a quelques conditions supplémentaires qui peuvent déclencher le problème, alors passons en revue le processus de dépannage suivant pour diagnostiquer et résoudre les problèmes aussi efficacement que possible:
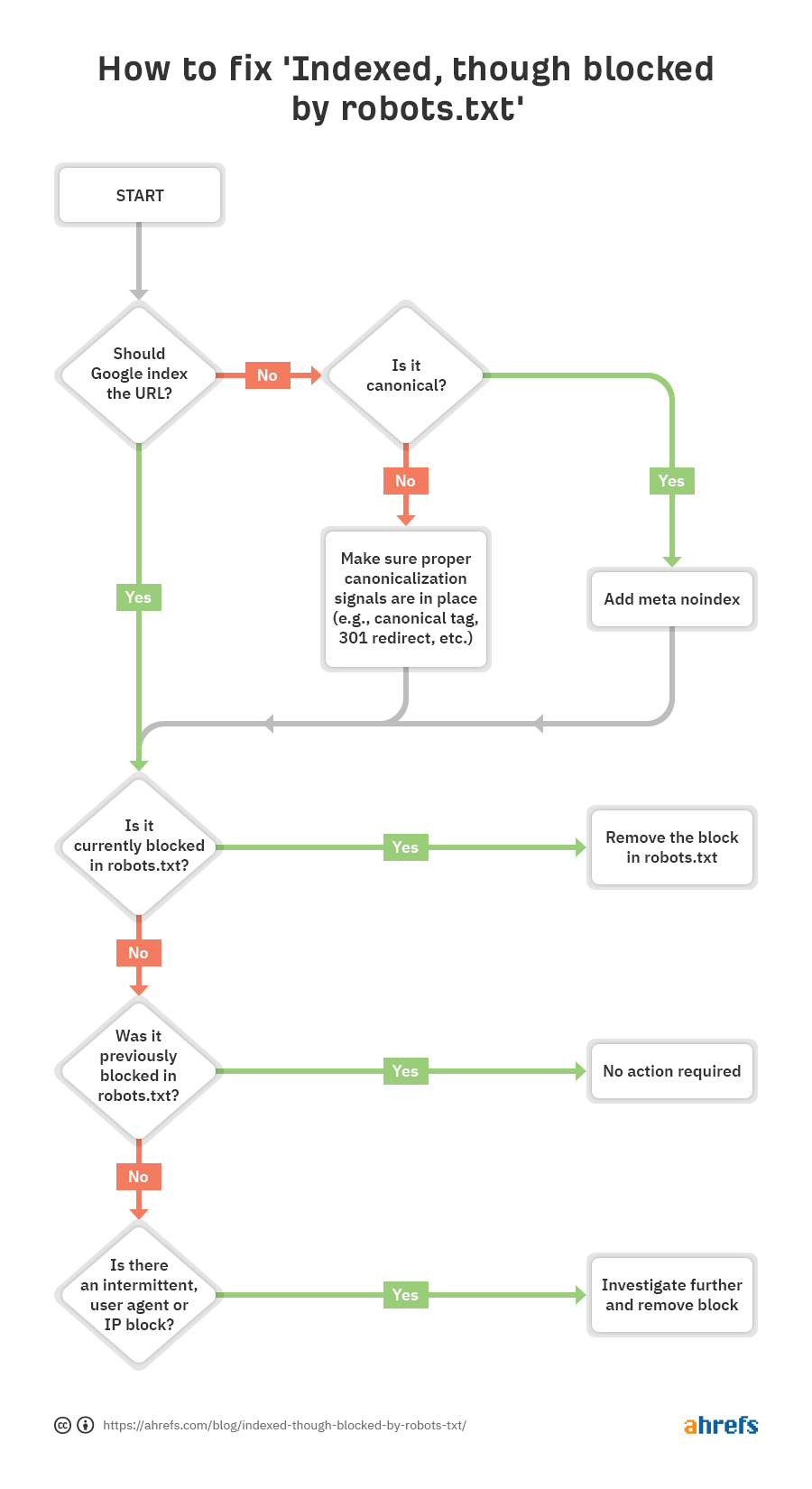

Vous pouvez voir que la première étape consiste à vous demander si vous souhaitez que Google indexe les URL.
Si vous ne voulez pas URL indexé…
Ajoutez simplement une balise Meta robots noindex et assurez-vous d’autoriser l’exploration, en supposant qu’elle soit canonique.
Si vous bloquez l’exploration d’une page, Google peut toujours l’indexer car l’exploration et l’indexation sont deux choses différentes. À moins que Google ne puisse explorer une page, il ne verra pas la balise Meta noindex et pourra toujours l’indexer car elle contient des liens.
Si la URL canonicalise vers une autre page, n’ajoutez pas de balise Meta robots noindex. Assurez-vous simplement que les signaux de canonisation appropriés sont en place, y compris une balise canonique sur la page canonique, et autorisez l’exploration pour que les signaux passent et se consolident correctement.
Si vous voulez le URL indexé…
Vous devez comprendre pourquoi Google ne peut pas explorer le URL et retirez le bloc.
La cause la plus probable est un bloc d’exploration dans le fichier robots.txt. Mais il existe quelques autres scénarios dans lesquels vous pouvez voir des messages indiquant que vous êtes bloqué. Passons en revue ces derniers dans l’ordre dans lequel vous devriez probablement les rechercher.
- Recherchez un bloc d’exploration dans le fichier robots.txt
- Vérifiez les blocs intermittents
- Rechercher un bloc user-agent
- Recherchez un IP bloquer
Recherchez un bloc d’exploration dans le fichier robots.txt
Le moyen le plus simple de voir le problème est d’utiliser le testeur robots.txt dans GSC, qui signalera la règle de blocage.
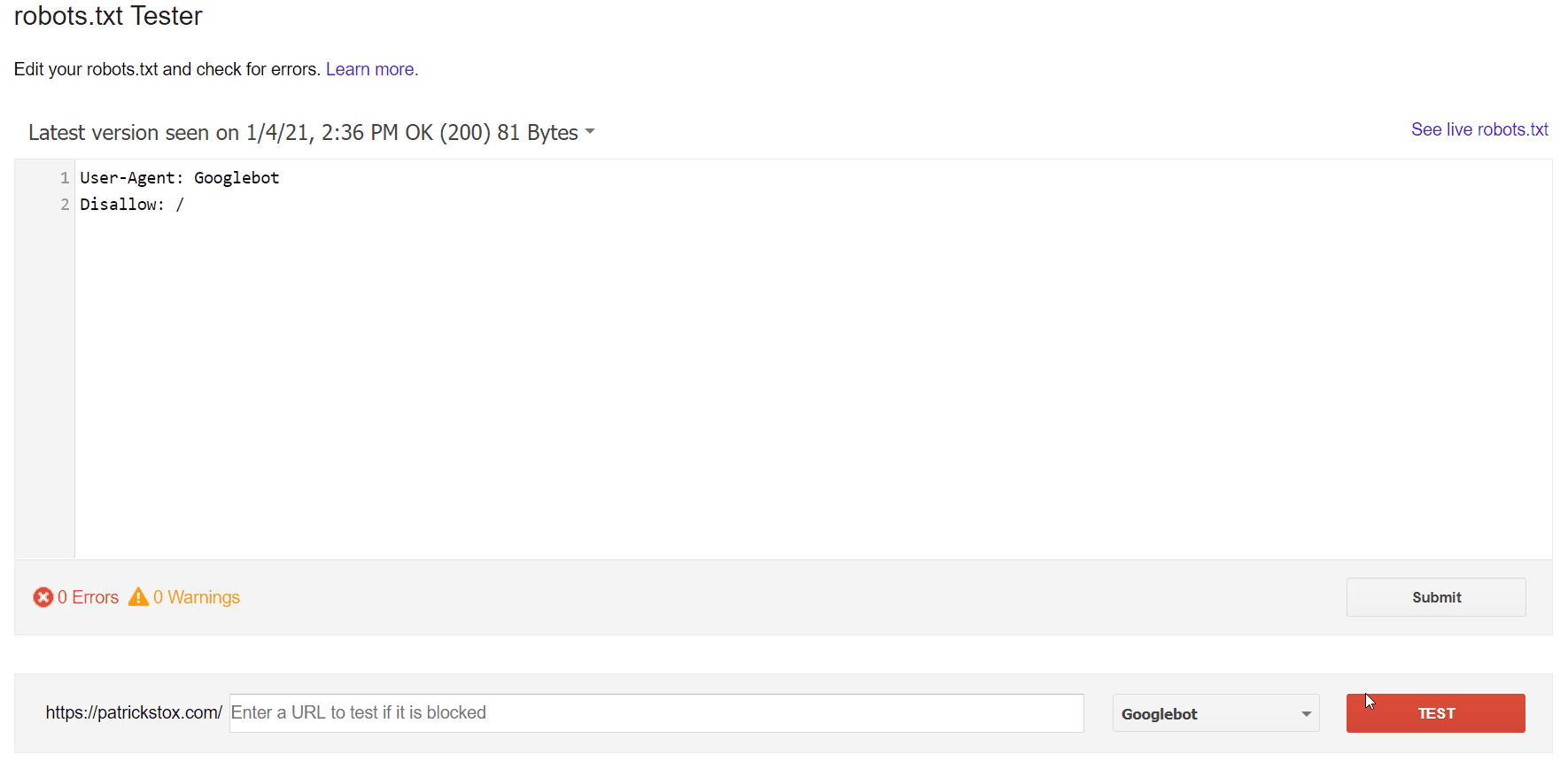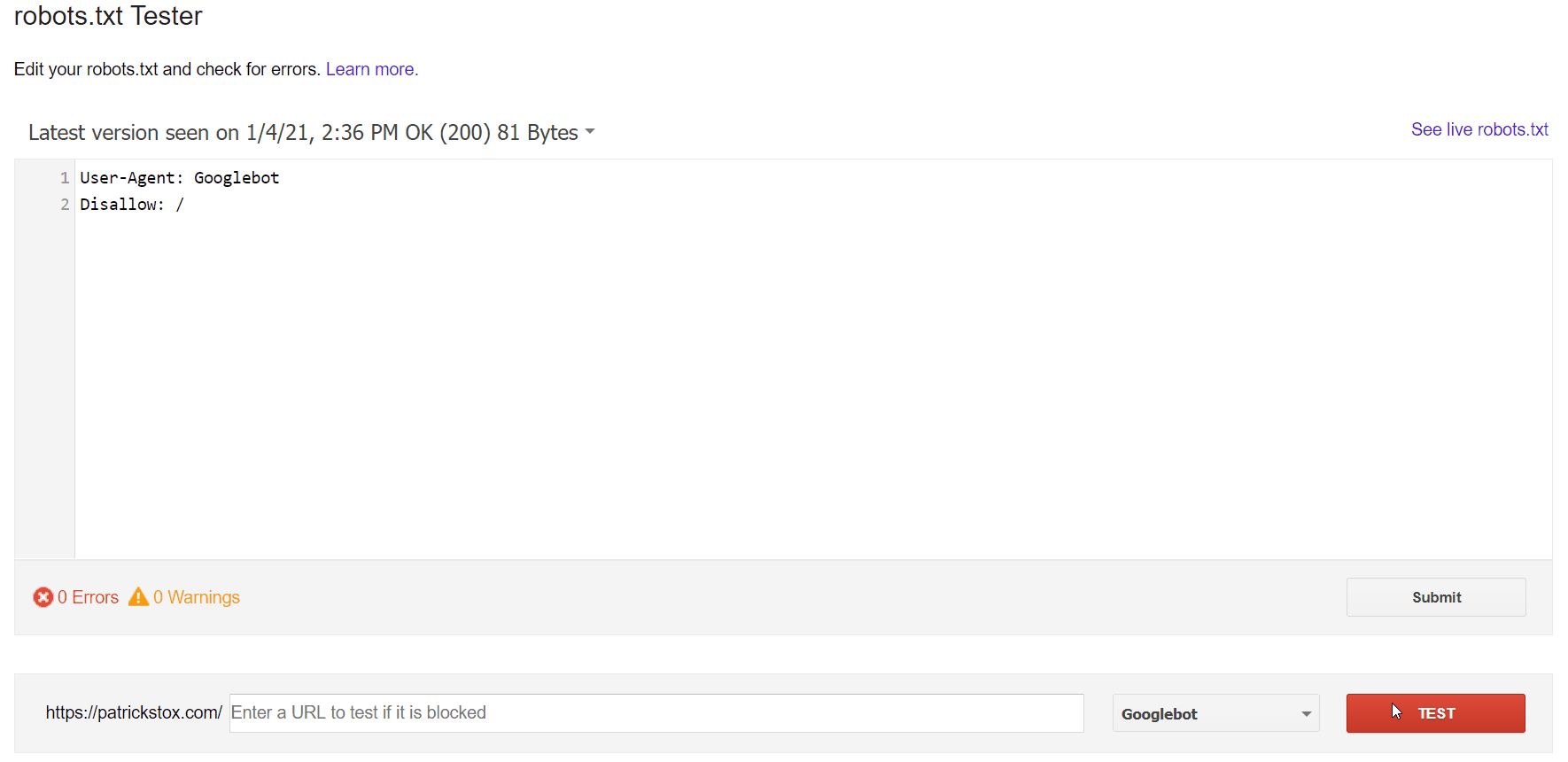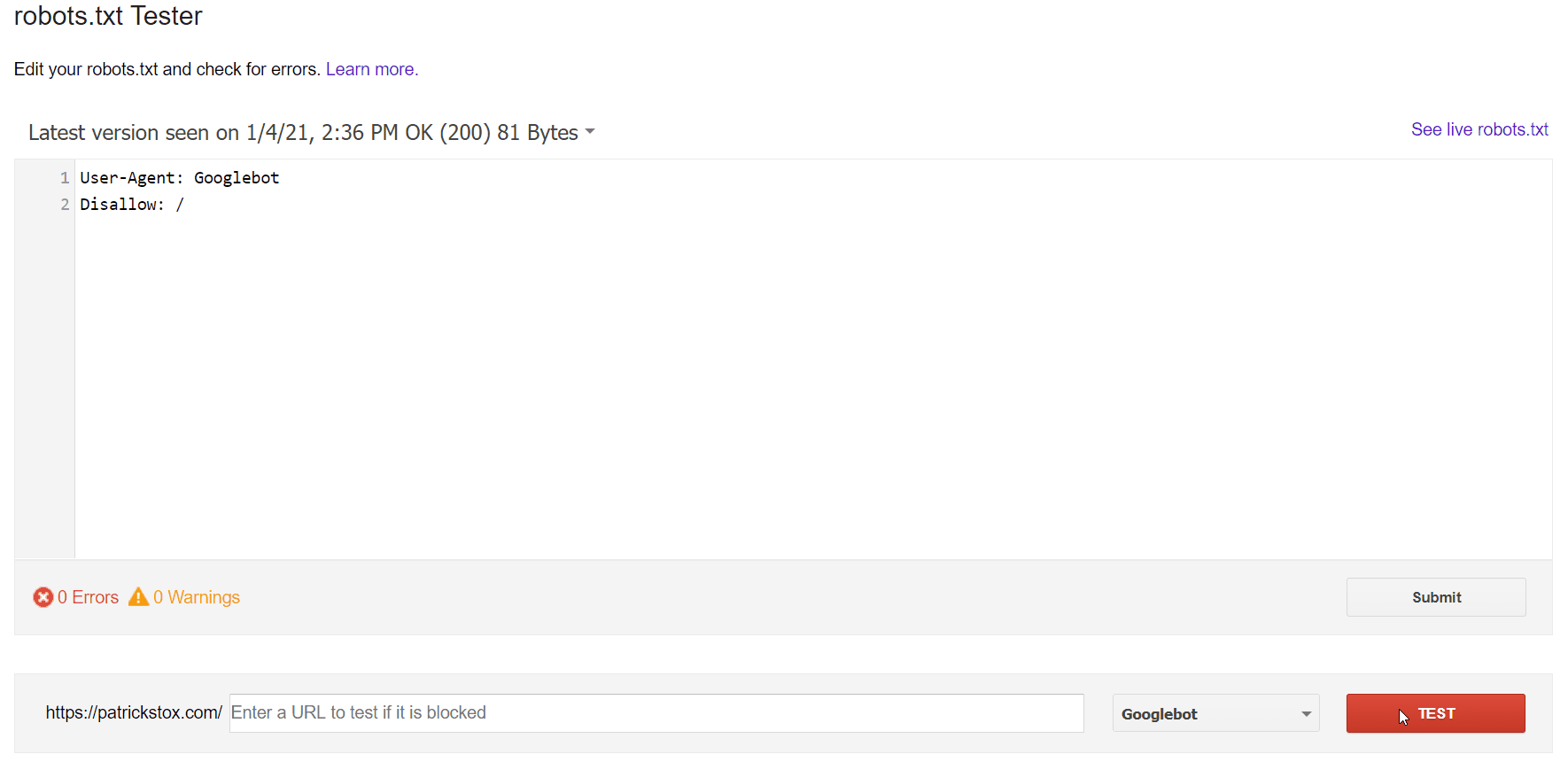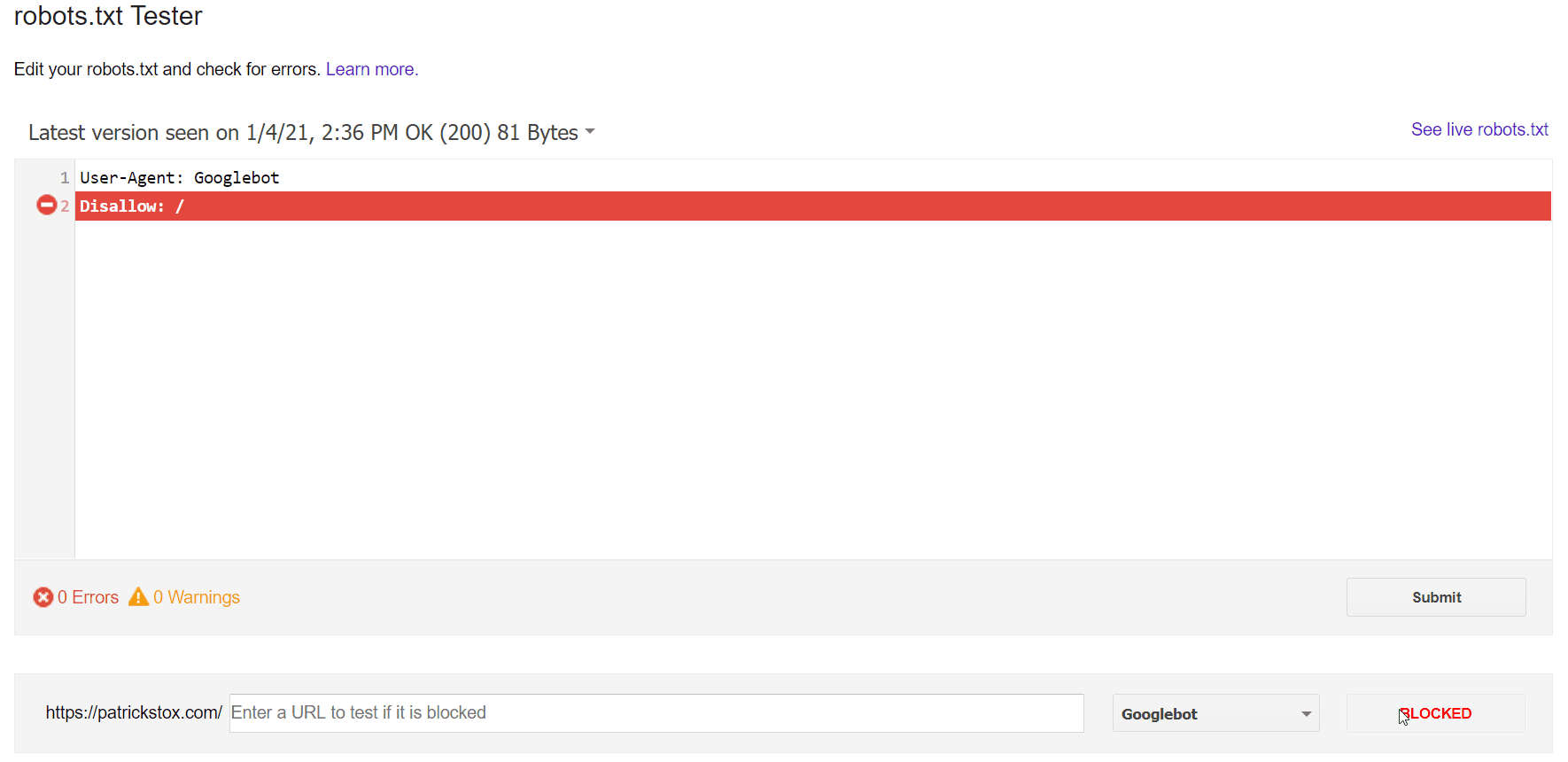
Si vous savez ce que vous recherchez ou si vous n’avez pas accès à GSC, vous pouvez accéder à domain.com/robots.txt pour trouver le fichier. Nous avons plus d’informations dans notre article sur le fichier robots.txt, mais vous recherchez probablement une déclaration d’interdiction telle que:
Disallow: /
Un user-agent spécifique peut être mentionné, ou il peut bloquer tout le monde. Si votre site est nouveau ou a été lancé récemment, vous pouvez rechercher:
User-agent: *
Disallow: /
Vous ne trouvez pas un problème?
Il est possible que quelqu’un ait déjà corrigé le bloc robots.txt et résolu le problème avant que vous ne l’examiniez. C’est le meilleur des cas. Cependant, si le problème semble être résolu mais réapparaît peu de temps après, vous pouvez avoir un blocage intermittent.
Comment réparer
Vous souhaiterez supprimer l’instruction d’interdiction à l’origine du blocage. La façon dont vous procédez varie en fonction de la technologie que vous utilisez.
WordPress
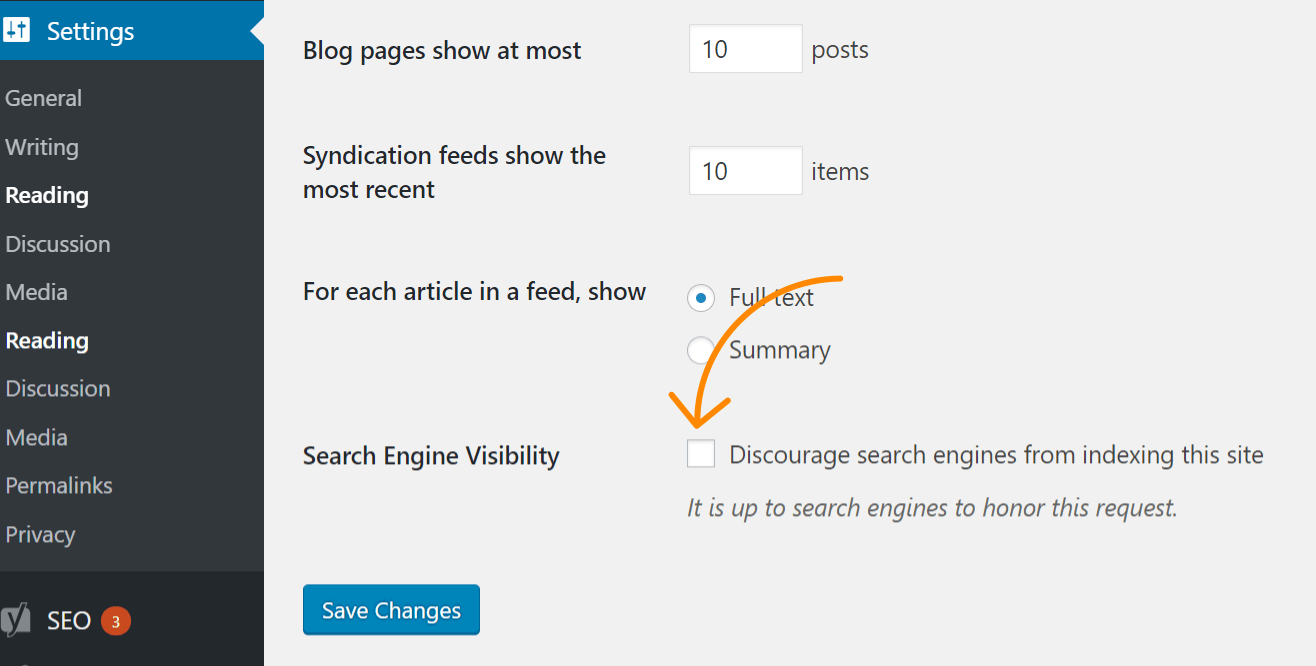
Si le problème affecte l’ensemble de votre site Web, la cause la plus probable est que vous avez vérifié un paramètre dans WordPress pour interdire l’indexation. Cette erreur est courante sur les nouveaux sites Web et après les migrations de sites Web. Suivez ces étapes pour le vérifier:
- Cliquez sur « Paramètres »
- Cliquez sur « Lecture »
- Assurez-vous que l’option « Visibilité sur les moteurs de recherche » n’est pas cochée.
WordPress avec Yoast
Si vous utilisez le Yoast SEO brancher, vous pouvez directement modifier le fichier robots.txt pour supprimer l’instruction de blocage.
- Cliquez sur « Yoast SEO»
- Cliquez sur « Outils »
- Cliquez sur « Éditeur de fichiers »
WordPress avec Rank Math
Similaire à Yoast, Mathématiques de rang vous permet de modifier directement le fichier robots.txt.
- Cliquez sur « Rank Math »
- Cliquez sur « Paramètres généraux »
- Cliquez sur « Modifier le fichier robots.txt »
FTP ou hébergement
Si tu as FTP accéder au site, vous pouvez modifier directement le fichier robots.txt pour supprimer l’instruction disallow à l’origine du problème. Votre fournisseur d’hébergement peut également vous donner accès à un gestionnaire de fichiers qui vous permet d’accéder directement au fichier robots.txt.
Vérifiez les blocs intermittents
Les problèmes intermittents peuvent être plus difficiles à résoudre car les conditions à l’origine du blocage peuvent ne pas toujours être présentes.
Ce que je recommande, c’est de vérifier l’historique de votre fichier robots.txt. Par exemple, dans la GSC testeur robots.txt, si vous cliquez sur le menu déroulant, vous verrez les anciennes versions du fichier sur lesquelles vous pouvez cliquer et voir ce qu’elles contenaient.

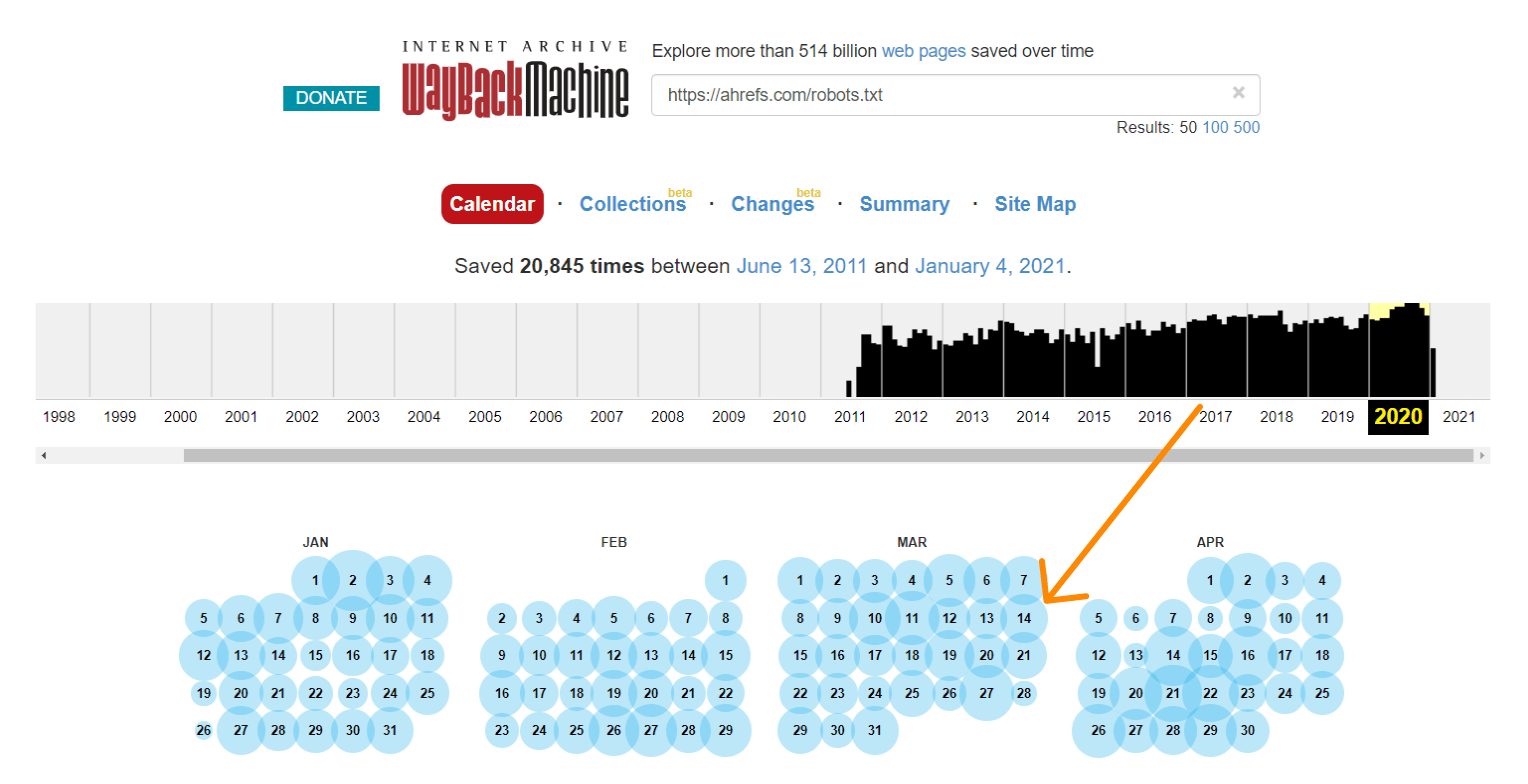
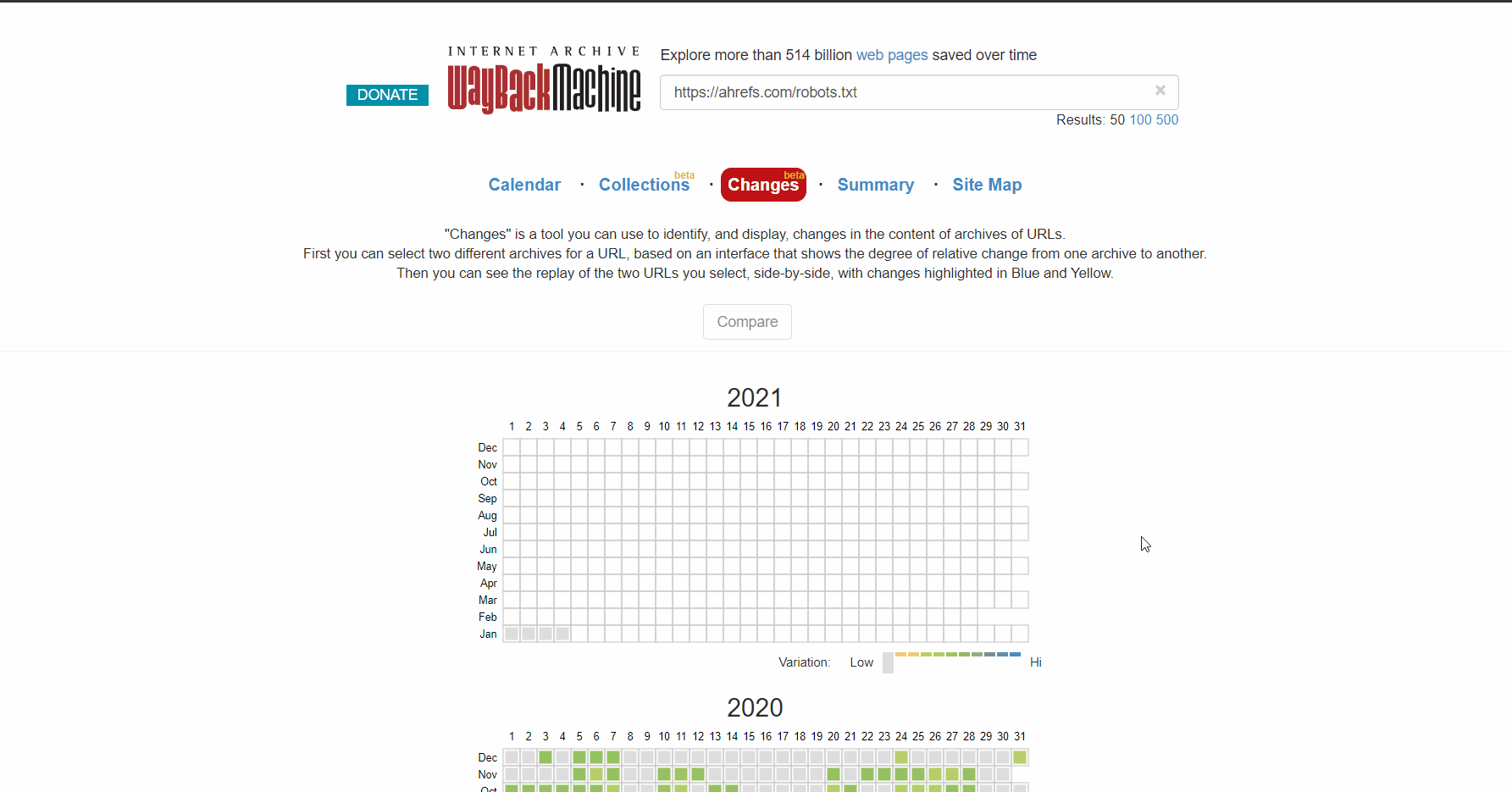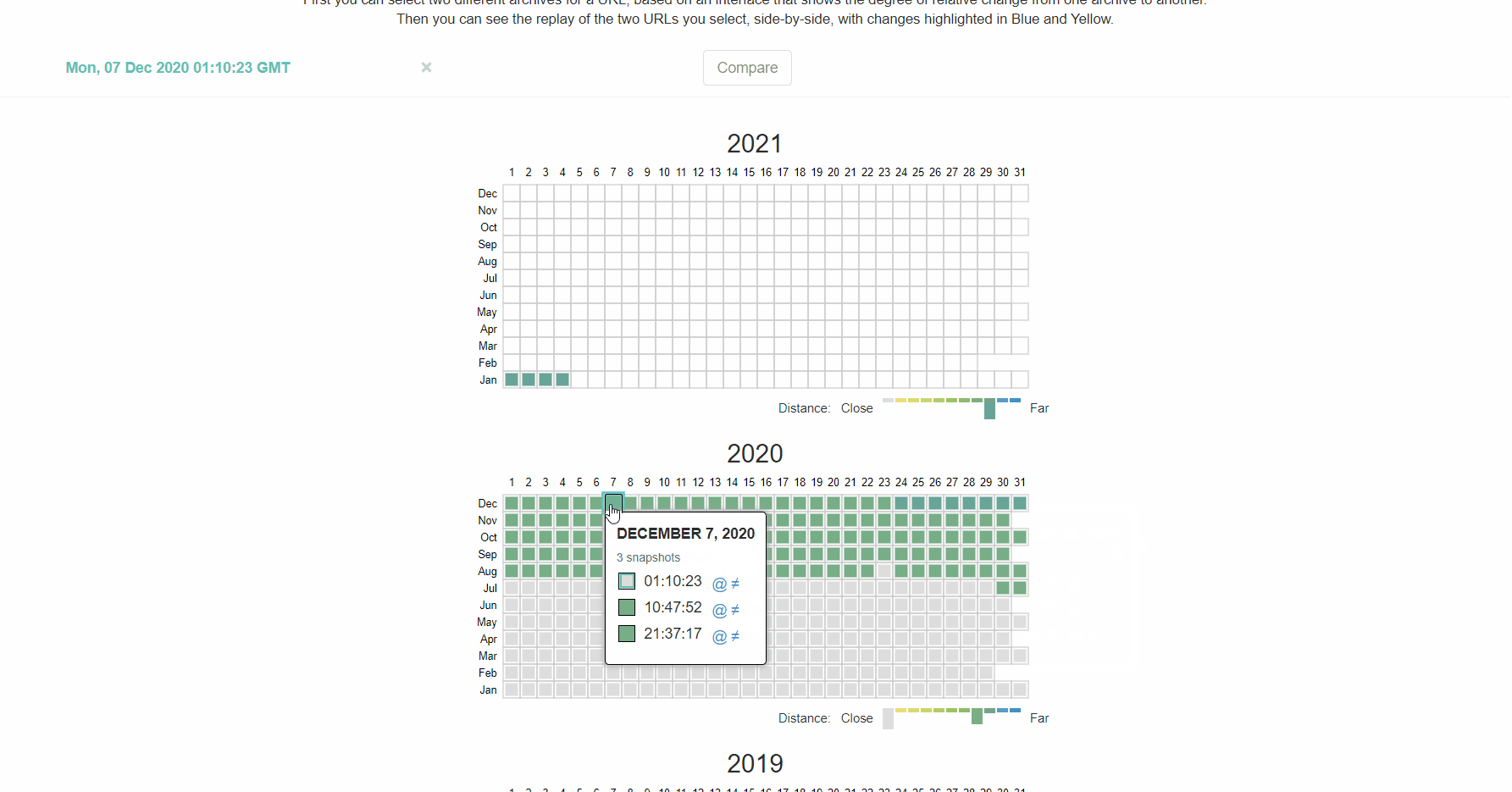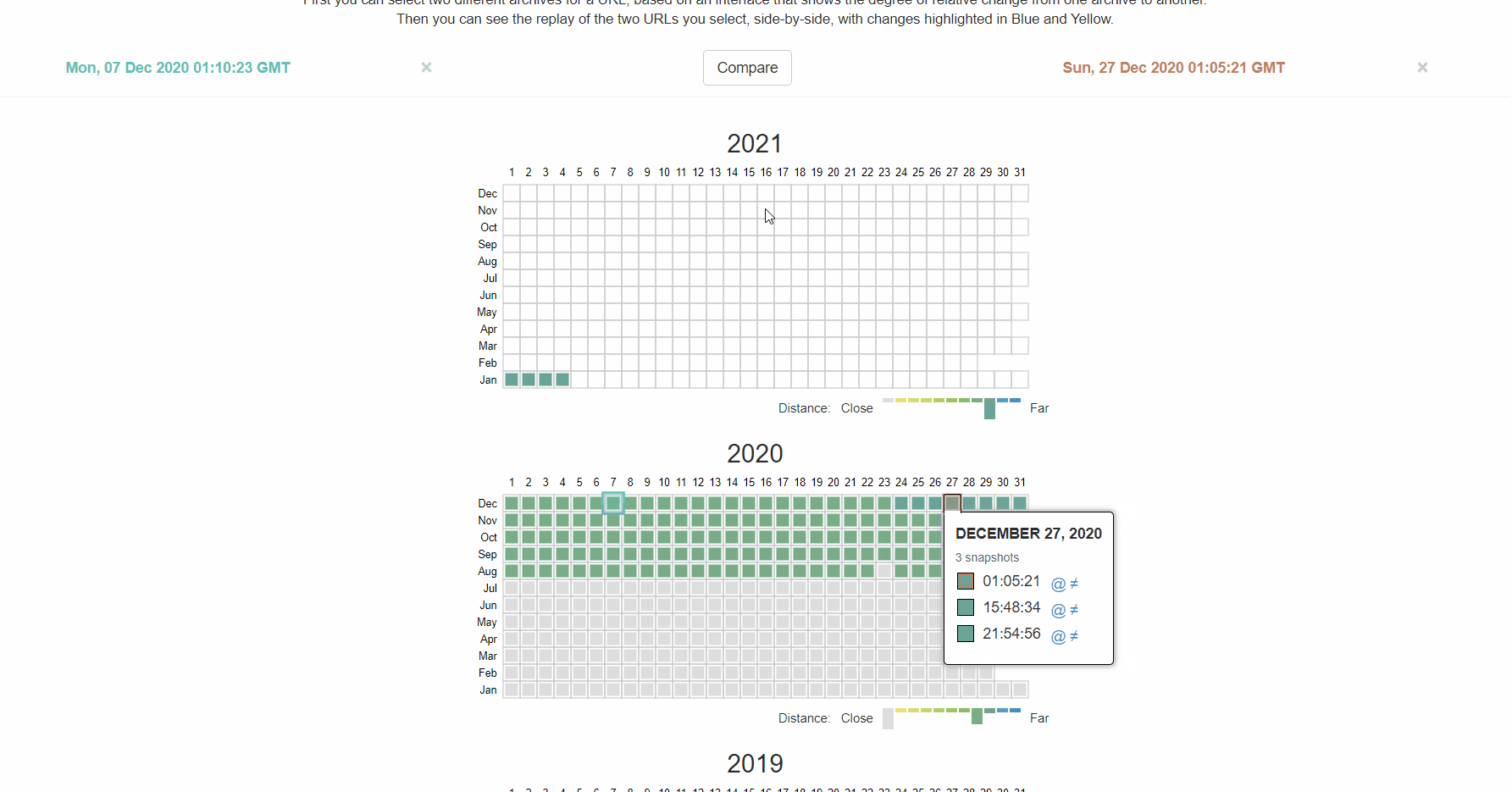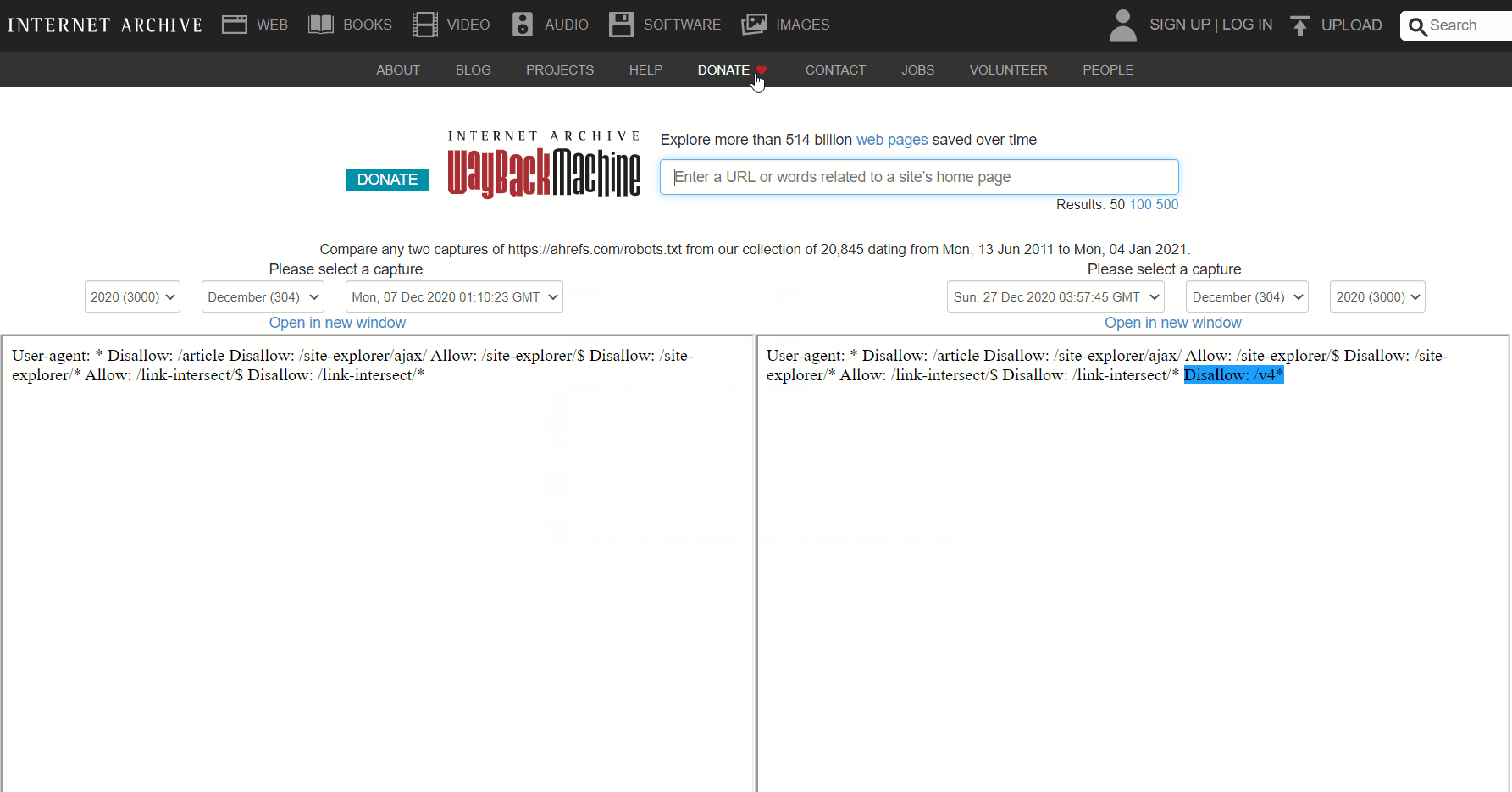
La machine de retour sur archive.org a également un historique des fichiers robots.txt pour les sites Web qu’ils explorent. Vous pouvez cliquer sur l’une des dates pour lesquelles ils ont des données et voir ce que le fichier a inclus ce jour-là.
Ou utilisez la version bêta du rapport sur les modifications, qui vous permet de voir facilement les modifications de contenu entre deux versions différentes.
Comment réparer
Le processus de correction des blocs intermittents dépendra de la cause du problème. Par exemple, une cause possible serait un cache partagé entre un environnement de test et un environnement en direct. Lorsque le cache de l’environnement de test est actif, le fichier robots.txt peut inclure une directive de blocage. Et lorsque le cache de l’environnement en direct est actif, le site peut être explorable. Dans ce cas, vous voudrez diviser le cache ou peut-être exclure les fichiers .txt du cache dans l’environnement de test.
Rechercher des blocs d’agent utilisateur
Les blocages d’agent utilisateur surviennent lorsqu’un site bloque un agent utilisateur spécifique comme Googlebot ou AhrefsBot. En d’autres termes, le site détecte un bot spécifique et bloque l’agent utilisateur correspondant.
Si vous pouvez afficher une page correctement dans votre navigateur habituel mais que vous êtes bloqué après avoir changé votre agent utilisateur, cela signifie que l’agent utilisateur spécifique que vous avez entré est bloqué.
Vous pouvez spécifier un agent utilisateur particulier à l’aide des outils de développement Chrome. Une autre option consiste à utiliser une extension de navigateur pour changer les agents utilisateurs comme Celui-ci.
Vous pouvez également rechercher des blocs d’agent utilisateur avec une commande cURL. Voici comment procéder sous Windows:
- Appuyez sur Windows + R pour ouvrir une boîte «Exécuter».
- Tapez « cmd » puis cliquez sur « D’accord. »
- Entrez une commande cURL comme celle-ci:
curl -A “user-agent-name-here” -Lv [URL]curl -A “Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)” -Lv https://ahrefs.com
Comment réparer
Malheureusement, c’est un autre domaine où savoir comment le résoudre dépendra de l’endroit où vous trouverez le bloc. De nombreux systèmes différents peuvent bloquer un bot, y compris .htaccess, la configuration du serveur, les pare-feu, CDN, ou même quelque chose que vous ne pourrez peut-être pas voir que votre fournisseur d’hébergement contrôle. Votre meilleur pari peut être de contacter votre fournisseur d’hébergement ou CDN et demandez-leur d’où vient le blocage et comment vous pouvez le résoudre.
Par exemple, voici deux façons différentes de bloquer un agent utilisateur dans .htaccess que vous devrez peut-être rechercher.
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} Googlebot [NC]RewriteRule .* - [F,L]
Ou…
BrowserMatchNoCase "Googlebot" bots
Order Allow,Deny
Allow from ALL
Deny from env=bots
Vérifier IP blocs
Si vous avez confirmé que vous n’êtes pas bloqué par le fichier robots.txt et que vous avez exclu les blocages d’agent utilisateur, il s’agit probablement d’un IP bloquer.
Comment réparer
IP les blocages sont des problèmes difficiles à repérer. Comme pour les blocs utilisateur-agent, votre meilleur pari peut être de contacter votre fournisseur d’hébergement ou CDN et demandez-leur d’où vient le blocage et comment vous pouvez le résoudre.
Voici un exemple de quelque chose que vous recherchez peut-être dans .htaccess:
deny from 123.123.123.123
Dernières pensées
La plupart du temps, l’avertissement «indexé, bien que bloqué par robots.txt» résulte d’un bloc robots.txt. J’espère que ce guide vous a aidé à trouver et à résoudre le problème si ce n’était pas le cas pour vous.
Avoir des questions? Faites-moi savoir sur Twitter.

